
Modern applications need data that's both accessible and fast. You have data in S3, but transforming it into usable insights requires complex ETL (extract-transform-load) pipelines. With our new livesync for S3 and pgai Vectorizer features, Timescale transforms how you interact with S3 data.
Two Powerful Postgres–S3 Integration Approaches

Our new features offer distinct approaches to working with S3 data:
- Livesync for S3 brings your structured S3 data directly into Postgres tables, automatically synchronizing files as they change.
- pgai Vectorizer leaves documents in S3 but generates searchable embeddings and metadata in Postgres, connecting unstructured content with structured data for RAG, search, and agentic applications.
Both eliminate complex ETL pipelines, letting you work with S3 data using familiar SQL.
Transform S3 to Analytics in Seconds: Automatic Data Synchronization With Livesync
S3 is where countless organizations store their data, but Timescale Cloud is where they unlock insights. Livesync for S3 bridges this gap, eliminating the traditional complexity of moving data between these systems.
The problem: Complex ETL pipelines for S3 data
Data management challenges create significant obstacles when bridging S3 storage and analytics environments. Organizations struggle with the manual effort required to transport data between S3 buckets and analytical databases, requiring custom integration code that demands ongoing maintenance. This challenge is compounded by the brittle and resource-intensive nature of maintaining ETL processes.
Many organizations find themselves caught in a constant battle to ensure data freshness, requiring vigilant monitoring systems to confirm that analytics platforms accurately reflect the most current information in S3 repositories. The culmination of these challenges frequently manifests as performance bottlenecks, where inefficient data transfer mechanisms cause critical delays in delivering up-to-date information to customer-facing applications, leading to poor user experiences and customers making decisions based on stale data.
The solution: Automatic data synchronization
Livesync for S3 bridges this gap, eliminating the traditional complexity of moving data between these systems. We've engineered livesync for S3 to bring stream-like behavior to object storage, effectively turning your S3 bucket into a continuous data feed.
Our solution delivers speed and simplicity:
- Zero-ETL experience : Eliminate complex pipelines or custom integration code.
- Real-time data pipeline : Turn your S3 bucket into a continuous data feed with automatic synchronization.
- Familiar tools : Use S3 for storage and Timescale Cloud for analytics without compromise.
- Minimal configuration : Connect to your S3 bucket, define mapping, and let livesync handle the rest.
How livesync works
Behind the scenes, we're doing the heavy lifting:
- Schema mapping that infers your data from CSV or Parquet files to hypertables
- Managing the initial data load
- Maintaining continuous synchronization
- Intelligent tracking of processed files to prevent duplicates or missed data
This enables teams across multiple industries to build robust pipelines. For organizations with production applications on Postgres looking to scale their real-time analytics, livesync for S3 has a sister solution—livesync for Postgres—which lets you keep your Postgres as-is while streaming data in real time to a Timescale Cloud instance optimized for analytical workloads.
The inner workings of livesync for S3
Secure cross-account authentication
Livesync employs a robust security model using AWS role assumption. Our service assumes a specific role in your AWS account with precisely the permissions needed to access your S3 data. To prevent confused deputy attacks, we implement the industry-standard External ID verification using your unique Project ID/Service ID combination.
Smart polling and file discovery
Behind the scenes, livesync intelligently scans your S3 bucket using optimized ListObjectsV2 calls. Starting with the prefix from your pattern (like "logs/" from "logs/**/*.csv"), it applies glob matching to find relevant files. The system tracks processed files in lexicographical order, ensuring no file is missed or duplicated.

To maintain performance, livesync for S3 manages an orderly queue limited to 100 files per connection. When files are plentiful, polling accelerates to every minute; when caught up, it follows your configured schedule. You can always trigger immediate processing with the "Pull now" button.
Optimized data processing pipeline
Livesync handles different file formats with specialized techniques:
- CSV files are analyzed for compression (UTF-8, ZIP, GZIP), then processed using high-performance parallel ingestion.
- Parquet files undergo efficient conversion before being streamed into TimescaleDB (which lives at the core of your Timescale Cloud service).
The entire pipeline includes intelligent error handling, which is clearly visible in the dashboard. After three consecutive failures, livesync automatically pauses to prevent resource waste, awaiting your review.
This architecture delivers the perfect balance of reliability, performance, and operational simplicity, bringing your S3 data into Timescale Cloud with minimal configuration and maximum confidence.
Build powerful ingest pipelines with minimal configuration:
- IoT telemetry flows: Connect devices that log to S3 (like AWS IoT Core) directly to time-series analytics.
- Streaming data persistence: Automatically process data from Kinesis, Kafka, or other streaming platforms that land files in S3 and transform into TimescaleDB hypertables for high-performance querying.
- Crypto/financial data analytics: Sync trading data from S3 into TimescaleDB for real-time analytics on recent market movements and long-term historical analysis for backtesting and trend identification.
Currently supporting CSV and Parquet file formats, livesync delivers a frictionless way to unlock the value of your data stored in S3.

Simple setup, powerful results
Livesync for S3 continuously monitors your S3 bucket for incoming sensor data, automatically maps schemas, and syncs data into TimescaleDB hypertables in minutes. This enables operators to query millions of readings with millisecond latency, driving real-time dashboards that catch anomalies before equipment fails. Livesync for S3 ensures that syncing from S3 to hypertables remains smooth, dependable, and lightning-fast.
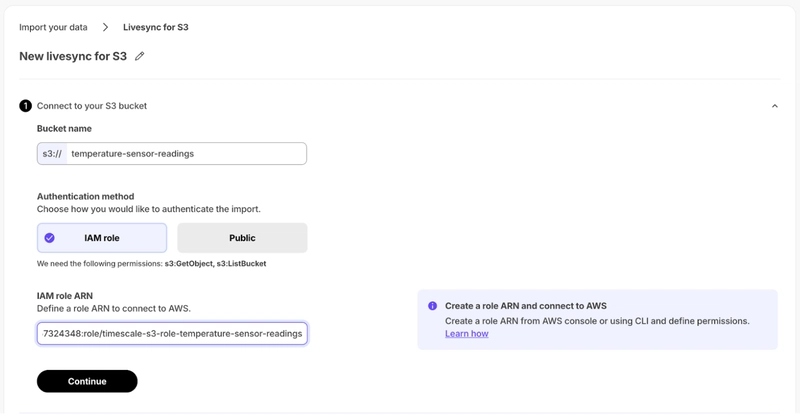
Setting up livesync for S3 is surprisingly straightforward:
- Connect to your S3 bucket with your credentials.
- Define how your objects map to TimescaleDB tables.
- Let livesync for S3 handle the rest—monitoring and ingesting new data automatically.
Behind the scenes, we're doing the heavy lifting of schema mapping, managing the initial data load, and maintaining continuous synchronization. The system intelligently tracks what it's processed, so you never have duplicate data or missed files.
For example, in manufacturing environments where sensors continuously capture critical equipment data through AWS IoT Core and store it in S3, livesync ensures this data becomes immediately queryable in TimescaleDB. This enables operators to identify anomalies before equipment fails, turning static S3 storage into actionable intelligence.
Zero maintenance, maximum performance
Once configured, livesync for S3 delivers ease and performance:
- Zero-maintenance operation once configured
- Schema mapping that infers your data from CSV or Parquet files to hypertables
- Automatic retry mechanisms for transient failures
- Fine-grained control over which objects sync and when
- Complete observability with detailed history of file imports and error messages (if any)
Simplify Document Embeddings With Pgai Vectorizer
Searching unstructured documents embeddings with pgvector
While livesync brings S3 data into Postgres, pgai Vectorizer takes a different approach for unstructured documents. It creates searchable vector embeddings in Postgres from documents stored in S3 while keeping the original files in place.
The problem: Complex pipelines for document search
AI applications using RAG (retrieval-augmented generation) can help businesses unlock insights from mountains of unstructured data. Today, that unstructured data’s natural home is Amazon S3. On the other hand, Postgres has become the default vector database for developers, thanks to extensions like pgvector and pgvectorscale. These extensions enable them to build intelligent applications with vector search capabilities without needing to use a separate database just for vectors.
We’ve previously written about how vector databases are the wrong abstraction because they divorce the source data from the vector embedding and lose the connection between unstructured data that's being embedded and the embeddings themselves. This problem is especially apparent for documents housed in object storage like Amazon S3.
Before pgai Vectorizer, developers typically needed to manage:
- Complex ETL pipelines to chunk, format, and create embeddings from source data
- Multiple systems: a vector database for embeddings, an application database for metadata, and possibly a separate lexical search index
- Data synchronization services to maintain a single source of truth
- Queuing systems for updates and synchronization
- Monitoring tools to catch data drift and handle rate limits from embedding services
- Alert systems for stale search results
- Validation checks across all these systems
Processing documents in AI pipelines introduces several challenges, such as managing diverse file formats (PDFs, DOCX, XLSX, HTML, and more), handling complex metadata, keeping embeddings up to date with document changes, and ensuring efficient storage and retrieval.
The solution: Automatic document vectorization
To solve these challenges, Timescale has added support for document vectorization to pgai Vectorizer, giving developers an automated way to create embeddings from documents in Amazon S3 and keep those embeddings synchronized as the underlying data changes, eliminating the need for external ETL pipelines and queuing systems.
Pgai Vectorizer provides a streamlined approach where developers can reference documents in S3 (or local storage) via URLs stored in a database table. The vectorizer then handles the complete workflow—downloading documents, parsing them to extract content, chunking text appropriately, and generating embeddings for use in semantic search, RAG, or agentic applications.
This integration supports a wide variety of file formats, including:
- Documents: PDF, DOCX, TXT, MD, AsciiDoc
- Spreadsheets: CSV, XLSX
- Presentations: PPTX
- Images: PNG, JPG, TIFF, BMP
- Web content: HTML
- Books: MOBI, EPUB
For developers, pgai Vectorizer for document vectorization offers three key benefits:
- Get started more easily → Automatic embedding creation with a simple SQL command manages the entire workflow from document reference to searchable embeddings.
- Spend less time wrangling data infrastructure → Automatic updating and synchronization of embeddings means your vector search stays current with your S3 documents without manual intervention. It’s as simple as adding a new row or updating a “modified_at” column in the documents table, and pgai Vectorizer will take off any (re)processing.
- Continuously improve your AI systems → Testing and experimentation with different embedding models or chunking strategies can be done with a single line of SQL, allowing you to optimize your application's performance.
By keeping your embeddings automatically synchronized to the source documents in S3, pgai Vectorizer ensures that your Postgres database remains the single source of truth for both your structured and vector data.
Under the hood: How pgai Vectorizer works with Amazon S3
Pgai Vectorizer simplifies the entire document processing pipeline through a streamlined architecture that connects your Amazon S3 documents with Postgres. Here's how it works:
Architecture overview

Architecture overview of pgai Vectorizer: The vectorizer system takes in source data from Postgres tables and S3 buckets, creates embeddings via worker processes running in AWS Lambda using user-specified parsing, chunking, and embedding configurations, and stores the final embeddings in Postgres tables using the pgvector data type.
The pgai Vectorizer architecture for document vectorization consists of several key components:
Data sources: Postgres and Amazon S3
- Text and metadata residing in Postgres tables
- Postgres tables containing URLs that reference documents in Amazon S3 (which serves as the data aggregation layer where your documents reside)
Vectorization configuration
- Stored in Postgres, allowing you to manage everything through familiar SQL commands
- Defines chunking strategies, embedding models, and processing parameters
Vectorizer worker (AWS Lambda)
- A daemon process that handles the actual work of processing documents
- Responsible for downloading, parsing, chunking, and embedding creation
- Automatically manages synchronization between source documents and embeddings
Destination
- All embeddings are stored in Postgres alongside metadata
- Enables unified queries across both structured data and vector embeddings
Document processing pipeline
The document vectorization process follows these steps:
- Documents are referenced via URLs stored in a database column.
- The vectorizer downloads documents using these URLs.
- Documents are parsed to extract text content in an embedding-friendly format.
- The content is chunked using configurable chunking strategies.
- Chunks are processed for embedding generation using your chosen embedding model.
- Embeddings are stored in Postgres with references to the source documents.

_ Pgai Vectorizer document processing pipeline showing how files in Amazon S3 get parsed, chunked, formatted, and embedded in order to be used in vector search queries in a Postgres database._
Key components
- Loader : Loads files from Amazon S3
- Parser : Extracts content from retrieved files, handling different document formats
- Chunking : Splits content into appropriate sizes for embedding models
- Formatting : Organizes chunks with metadata from the source files
- Embedding generator : Processes chunks into vector embeddings
Use cases for pgai Vectorizer document vectorization
Pgai Vectorizer's document vectorization capabilities enable several powerful use cases across industries by connecting S3-stored documents with Postgres vector search:
Financial analysis
Automatically vectorize financial documents from S3 without custom pipelines. Connect document insights with quantitative metrics for unified queries.
Legal document management
Maintain synchronized knowledge bases of legal documents with automatic embedding updates. Test different models for your specific domain.
Enhanced customer support
Make knowledge base content immediately searchable as it changes, connecting support documents with customer data.
Research systems
Build research AI with continuously updated paper collections, connecting published findings with experimental time-series data.
In each case, pgai Vectorizer eliminates infrastructure complexity while enabling continuous improvement through its "set it and forget it" synchronization and simple experimentation capabilities.
Try out the S3 features in Timescale Cloud Today
Livesync and pgai Vectorizer are just the first steps in our vision to unify Postgres and object storage into a single, powerful lakehouse-style architecture—built for real-time AI and analytics.
→ Sign up for Timescale Cloud and get started in seconds.
We can’t wait to see what you build.
Day 4 preview: Developer Tools That Speed Up Your Workflow: Introducing SQL Assistant, Recommendation Engine, and Insights
Tomorrow, we'll reveal how Timescale delivers high-speed performance without sacrificing simplicity through SQL assistant with agent mode , recommendation engine , and Insights. See how plain-language queries eliminate SQL wrangling, how automated tuning keeps databases optimized with a single click, and why developers finally get both the millisecond response times users demand and the operational simplicity teams need.

Top comments (0)