AI becomes more popular in the last 3 years. Different Large language models (GPT, Llama, Gemini, Claude, Nova) are developed by giant companies (OpenAI, Meta, Google, Anthropic, AWS, Mistral). While developing, do you know how they automate, validate, monitor?
Are you curious about what is going on in the back (kitchen)?
Table of Contents
- What is MLOps?
- Motivation: Why is MLOps Important?
- MLOps Architecture
- MLOps Tools Comparison Table
- Best Practices in MLOps
- Conclusion
- References
What is MLOps?
MLOps (Machine Learning Operations) is a set of practices that combine Machine Learning (ML), DevOps, and Data Engineering to deploy and maintain ML systems reliably and efficiently in production.
It aims to:
-
Automate the ML lifecyclefrom data to deployment. -
Version,validate, and monitor modelscontinuously. - Enable collaboration between data scientists, ML engineers, and operations teams.
You can think of it as DevOps for machine learning, but with unique complexities such as model drift, data quality, and reproducibility.
There are 3 steps for MLOps:
- MLOps level 0: Manual process
- MLOps level 1: ML pipeline automation
- MLOps level 2: CI/CD pipeline automation
Motivation: Why is MLOps Important?
Without MLOps:
- Models stay in notebooks, never reaching production.
- Retraining models is manual and error-prone.
- No traceability of data or models.
- Hard to scale experiments or collaborate.
With MLOps:
- Models can be deployed reliably and quickly.
- Enables CI/CD for ML pipelines.
- Provides traceability and governance.
- Ensures monitoring and retraining loops are in place.
Companies need MLOps to turn their ML investments into real, scalable, and maintainable products.
MLOps Architecture
MLOps level 2: CI/CD pipeline automation
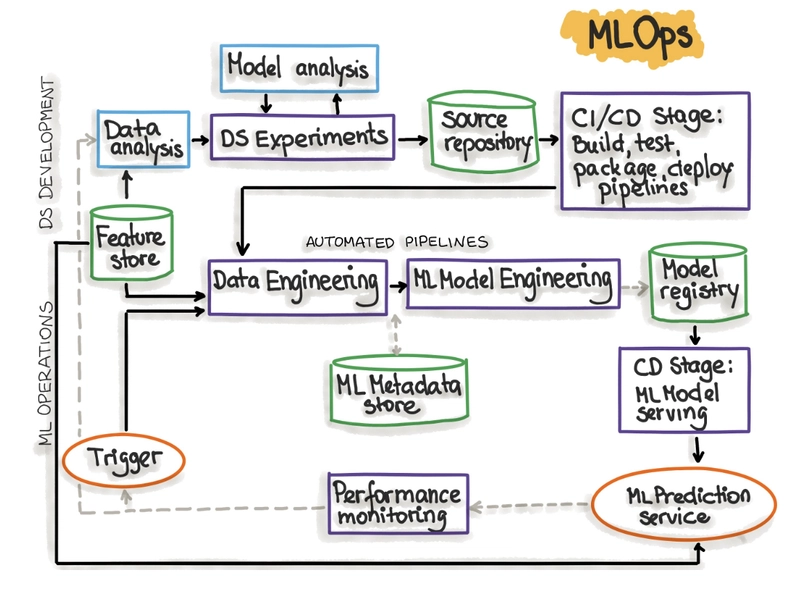
Ref: https://ml-ops.org/content/mlops-principles
-
Orchestrated Experimentation: Collaborative, tracked experimentation:
- Data Validation
- Data Preparation
Model Training- Model Evaluation
- Model Validation
-
CI 1 - ML Train, Test, Package: Automating code integration and model packaging. "You
build source code and run various tests. The outputs of this stage are pipeline components (packages, executables, and artifacts) to be deployed in a later stage." (Ref: Google) -
CD 1 - Pipeline Deployment: Deploying pipelines into various environments. "You deploy the artifacts produced by the CI stage to the target environment. The output of this stage is a
deployed pipeline with the new implementation of the model." (Ref: Google) -
CI 2 - Full Automated: ML Production Training Pipeline: End-to-end pipeline (ETL → Train → Validate) for production."The pipeline is automatically executed
in production based on a schedule or in response to a trigger. The output of this stage is a trained model that is pushed to the model registry." (Ref: Google)- Data Extraction
- Data Validation
- Data Preparation
- Model Training
- Model Evaluation
- Model Validation
-
CD 2 - Model Production Serving:
Exposing models as APIsor batch processors. -
Monitoring & Retraining:
Keeping models accurateand fresh.
Difference MLOps level 1 & 2: Implementing CI/CD pipeline for the Orchestrated Experimentation. In level 1, orchestrated experiment run manually, not in pipelines.
Above figure shows the steps and tools for MLOps. Now, we’re focusing on each part with different subtitles. Let’s dive..
Feature Store
A Feature Store is a centralized repository for storing, managing, and sharing features used in machine learning models both for training and real-time inference.
-
Feature: A feature is an individual
measurable property or characteristicused by a machine learning model to make predictions. -
Raw Data: Raw data is the original,
unprocessed informationcollected from various sources, which may need cleaning or transformation before being used. -
Feature vs Raw Data:
Features are derived from raw datathrough preprocessing steps to make the data suitable for training machine learning models.
Why it's important:
- Ensures consistency between training and inference.
- Promotes feature reuse across teams.
- Reduces duplication and errors in feature engineering.
| Platform | Tool |
|---|---|
| On-prem | Feast, DVC |
| AWS | SageMaker Feature Store |
| GCP | Vertex AI Feature Store |
| Azure | Azure ML Feature Store |
Orchestrated Experiment
This is the initial phase where data scientists run experiments to analyze data, test models, and record experiment metadata.
| Platform | Tool |
|---|---|
| On-prem | JupyterLab + MLFlow (or Weights & Biases) |
| AWS | SageMaker Studio + SageMaker Experiments |
| GCP | Vertex AI Workbench + Vertex AI Experiments |
| Azure | Azure ML Studio + Azure ML SDK |
CI 1 - ML Train, Test, Package
This step handles Continuous Integration for ML Code: Testing code, building ML components (models), and packaging them into containers or artifacts.
| Platform | Tool |
|---|---|
| On-prem | GitLab/GitHub Pipelines (or Jenkins) + Container + MLFlow (or Weights & Biases) |
| AWS | CodeBuild + CodePipeline + ECR |
| GCP | Cloud Build + Artifact Registry |
| Azure | Azure DevOps Pipelines + Container Registry |
CD 1 - Pipeline Deployment
Deploying the ML pipeline (not the model yet) — to dev/staging/prod environments.
| Platform | Tool |
|---|---|
| On-prem | GitLab/GitHub Pipelines + Container + MLFlow (or Weights & Biases) |
| AWS | SageMaker Pipelines + CodePipeline + Container |
| GCP | Vertex AI Pipelines + Cloud Composer + Container |
| Azure | Azure ML Pipelines + Azure DevOps + Container |
ML Metadata Store - Experiment Tracking
An ML Metadata Store records metadata generated during the ML lifecycle — data lineage, model hyperparameters, training run IDs, evaluation metrics, and more.
Why it's important:
- Enables experiment reproducibility.
- Helps trace the origin and evolution of models.
- Supports automated model governance and auditing.
| Platform | Tool |
|---|---|
| On-prem | MLFlow (or Weights & Biases) |
| AWS | SageMaker Experiments |
| GCP | Vertex AI Experiments |
| Azure | Azure ML Experiments & Run History |
CI 2 - Full Automated: ML Production Training Pipeline
- Full ML pipeline: Data extraction, validation, preprocessing, training, evaluation, validation.
- In ML, code doesn't always change, but data or features do — and that alone can trigger new training runs. So having separate pipelines for:
- Pipeline deployment (i.e., re-train when data changes).
- Build & test a training pipeline (which depends on fresh data, features, and compute)
| Platform | Tool |
|---|---|
| On-prem | Airflow + GitLab/GitHub Pipelines + MLFlow + Container |
| AWS | SageMaker Pipelines + Container |
| GCP | Vertex AI Pipelines + Container |
| Azure | Azure ML Pipelines + Container |
Model Registry
A Model Registry is like a version-controlled catalog of models. It tracks model versions, metadata, stage (e.g., staging, production), and lifecycle.
Why it's important:
- Keeps track of all trained models.
- Manages promotion between environments (dev → staging → prod).
- Enables collaboration between data science and operations teams.
| Platform | Tool |
|---|---|
| On-prem | MLFlow Model Registry |
| AWS | SageMaker Model Registry |
| GCP | Vertex AI Model Registry |
| Azure | Azure ML Model Registry |
CD 2 - Model Production Serving
- Serving the trained model in production (e.g., real-time API, batch inference).
- In ML, code doesn't always change, but data or features do — and that alone can trigger new training runs. So having separate pipelines for:
- Model serving (deploy newly trained model for inference) is crucial.
| Platform | Tools |
|---|---|
| On-prem | MLFlow Server, KServe, Seldon Core, TorchServe |
| AWS | SageMaker Endpoints |
| GCP | Vertex AI Prediction |
| Azure | Azure ML Endpoints |
Performance Monitoring
Monitoring model performance post-deployment for drift, accuracy, latency, etc. It may also trigger retraining.
| Platform | Tools |
|---|---|
| On-prem | Prometheus + Grafana, MLFlow |
| AWS | SageMaker Model Monitor |
| GCP | Vertex AI Model Monitoring |
| Azure | Azure Monitor + Azure ML Data Drift Monitor |
MLOps Tools Comparison Table
| Stage | On-Premise (Open Source) | AWS | GCP | Azure |
|---|---|---|---|---|
| Feature Store | Feast, DVC | SageMaker Feature Store | Vertex AI Feature Store | Azure Feature Store (in preview) |
| Orchestrated Experiment | JupyterLab, MLFlow (or Weights & Biases) | SageMaker Pipelines | Vertex AI Pipelines | Azure ML Pipelines |
| CI 1 - ML Train, Test, Package | GitLab/GitHub Pipelines (or Jenkins) + Container + MLFlow (or Weights & Biases) | AWS CodeBuild + CodePipeline + ECR + Container | Cloud Build + Container | Azure DevOps + GitHub Actions + Container |
| CD 1 – Pipeline Deployment | GitLab/GitHub Pipelines + Container + MLFlow (or Weights & Biases) | SageMaker Pipelines + CodePipeline + Container | Vertex AI Pipelines + Cloud Composer + Container | Azure ML Pipelines + Azure DevOps + Container |
| ML Metadata Store – Experiment Tracking | MLFlow (or Weights & Biases) | SageMaker Experiments | Vertex AI Experiments | Azure ML Tracking |
| CI 2 - Full Automated: ML Production Training Pipeline | Airflow + GitLab/GitHub Pipelines + MLFlow + Container | SageMaker Pipelines + Container | Vertex AI Pipelines + Container | Azure ML Pipelines + Container |
| Model Registry | MLFlow Registry, ModelDB | SageMaker Model Registry | Vertex AI Model Registry | Azure ML Model Registry |
| CD 2 - Model Production Serving | MLFlow Server, KServe, Seldon Core, TorchServe | SageMaker Endpoints | Vertex AI Prediction | Azure ML Endpoints |
| Performance Monitoring | Prometheus + Grafana, MLFlow | SageMaker Model Monitor | Vertex AI Model Monitoring | Azure Data Collector + Monitor |
Best Practices in MLOps
-
Track Everything:
Data, ML Code, ML Models, Evaluation Metrics. -
Use Feature Stores: For
consistency across training and inference. -
Automate Pipelines:
Reduce manual errorsand increase reproducibility. -
CI/CD for ML: Use
automated tests and deployments for ML codeand models. -
Monitor Continuously:
Detect drift, anomalies, or failuresearly. - Model Governance: Ensure auditability, compliance, and security.
- Decouple Components: Modularize training, serving, monitoring.
Conclusion
In today’s AI-driven world, building a model is no longer the hard part, deploying, maintaining, and scaling it is. That’s where MLOpscomes in. It bridges the gap between data science and operations, enabling teams to move from experimentation to production efficiently, reliably, and repeatedly.
Why MLOps Is Important
- Consistency: Ensures your model behaves the same in training and production.
- Reproducibility: Tracks experiments, datasets, and model versions.
- Speed: Automates repetitive steps like training, testing, and deployment.
- Monitoring: Detects model drift, performance issues, and data quality problems.
- Collaboration: Connects data scientists, ML engineers, and DevOps through a shared workflow
If you found this post interesting, I’d love to hear your thoughts in the blog post comments. Feel free to share your reactions or leave a comment. I truly value your input and engagement 😉
References
- https://ml-ops.org/content/mlops-principles
- Google: https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
Your comments 🤔
- Which tools are you using? Please mention in the comment your experience, your interest?
- What are you thinking about MLOps?



Top comments (7)
honestly i always get confused with all the pipelines and model stuff, but this helps a bit - i still gotta figure out which tools fit me best tho
Basically, 1st CI/CD to train better ML Model while development/data science phase; 2nd one is if there is concept/data drift (change) in prod, to build/train/deploy again automatically 😊
incredible breakdown
thanks :)
Really appreciate the hands-on comparison of MLOps tools across the different cloudsI've bounced between SageMaker and Vertex AI a lot, so seeing them side by side is super helpful.
thanks, I tried to cover the MLOps tools on different platforms..
In my experience, MLOps enables fast experimentation, automated training, and reliable deployment, which are crucial for getting models into production efficiently, quickly, reliably.