

Void is an open-source alternative to Cursor — a fast, privacy-first AI code editor built on top of VS Code. With Void, you can run any LLM (local or cloud), use advanced AI agents on your codebase, track changes with checkpoints, and integrate seamlessly with providers like Ollama, Claude, DeepSeek, OpenAI, and more — all without your data ever leaving your machine.
It brings features like:
- Autocomplete with Tab
- Inline Quick Edit
- Chat + Agent Mode + Gather Mode
- Full control over which models you use and how
Whether you’re a privacy-conscious dev, a tinkerer with local models, or someone who just wants to break free from backend lock-ins — Void is your playground.
This project is fully open source under the Apache 2.0 License. If you’re an open-source contributor, you’re more than welcome to join in and help shape the future of AI coding tools!
Resources
Website
Link: https://voideditor.com/
GitHub
Link: https://github.com/voideditor/void
Step-by-Step Process to Setup Void + Ollama + LLMs
For the purpose of this tutorial, we will use a GPU-powered Virtual Machine offered by NodeShift; however, you can replicate the same steps with any other cloud provider of your choice. NodeShift provides the most affordable Virtual Machines at a scale that meets GDPR, SOC2, and ISO27001 requirements.
Step 1: Sign Up and Set Up a NodeShift Cloud Account
Visit the NodeShift Platform and create an account. Once you’ve signed up, log into your account.
Follow the account setup process and provide the necessary details and information.
Step 2: Create a GPU Node (Virtual Machine)
GPU Nodes are NodeShift’s GPU Virtual Machines, on-demand resources equipped with diverse GPUs ranging from H100s to A100s. These GPU-powered VMs provide enhanced environmental control, allowing configuration adjustments for GPUs, CPUs, RAM, and Storage based on specific requirements.
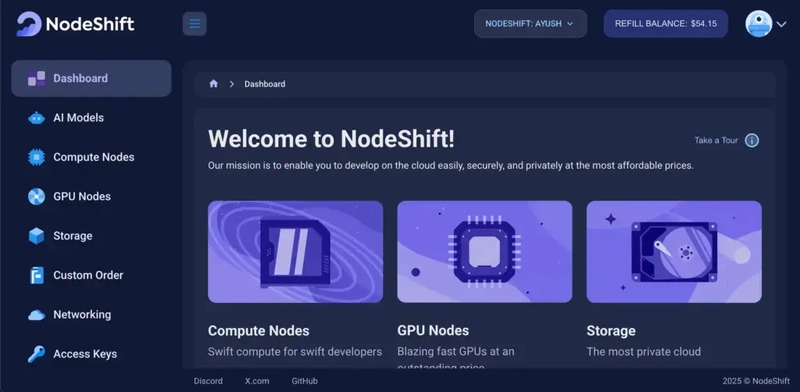

Navigate to the menu on the left side. Select the GPU Nodes option, create a GPU Node in the Dashboard, click the Create GPU Node button, and create your first Virtual Machine deploy
Step 3: Select a Model, Region, and Storage
In the “GPU Nodes” tab, select a GPU Model and Storage according to your needs and the geographical region where you want to launch your model.
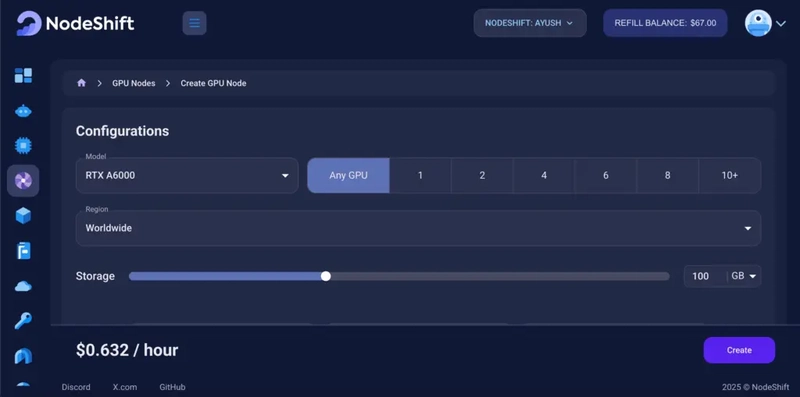

We will use 1 x RTXA6000 GPU for this tutorial to achieve the fastest performance. However, you can choose a more affordable GPU with less VRAM if that better suits your requirements.
Step 4: Select Authentication Method
There are two authentication methods available: Password and SSH Key. SSH keys are a more secure option. To create them, please refer to our official documentation.

Step 5: Choose an Image
Next, you will need to choose an image for your Virtual Machine. We will deploy tool on an NVIDIA Cuda Virtual Machine. This proprietary, closed-source parallel computing platform will allow you to install tool on your GPU Node.

After choosing the image, click the ‘Create’ button, and your Virtual Machine will be deployed.

Step 6: Virtual Machine Successfully Deployed
You will get visual confirmation that your node is up and running.

Step 7: Connect to GPUs using SSH
NodeShift GPUs can be connected to and controlled through a terminal using the SSH key provided during GPU creation.
Once your GPU Node deployment is successfully created and has reached the ‘RUNNING’ status, you can navigate to the page of your GPU Deployment Instance. Then, click the ‘Connect’ button in the top right corner.
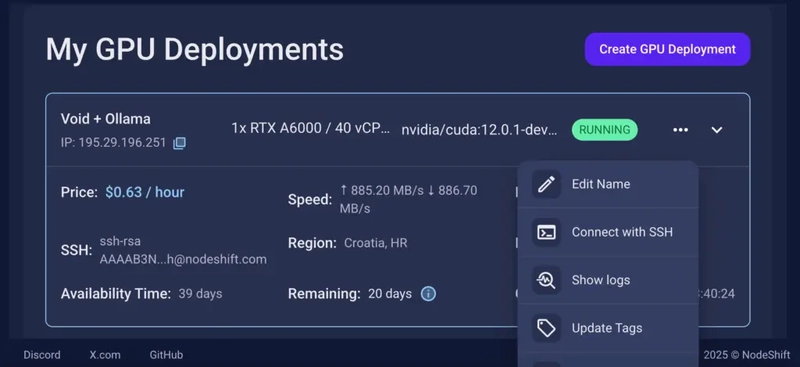
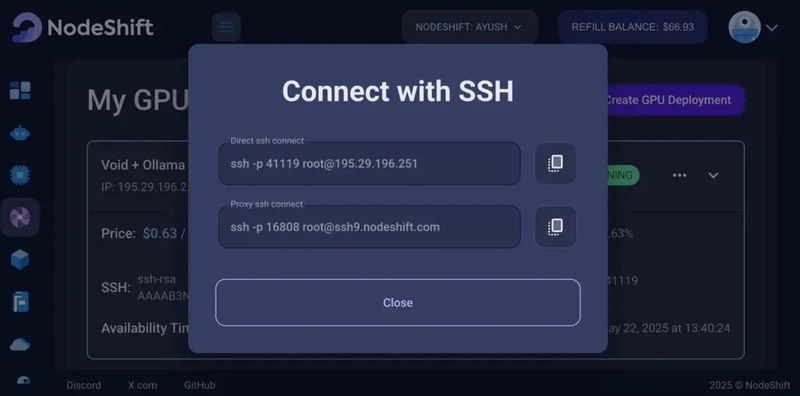
Now open your terminal and paste the proxy SSH IP or direct SSH IP.
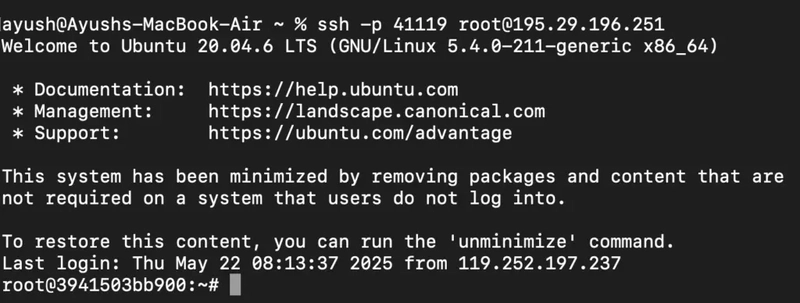
Next, if you want to check the GPU details, run the command below:
nvidia-smi

Step 8: Install Ollama
After connecting to the terminal via SSH, it’s now time to install Ollama from the official Ollama website.
Website Link: https://ollama.com/
Run the following command to install the Ollama:
curl -fsSL https://ollama.com/install.sh | sh
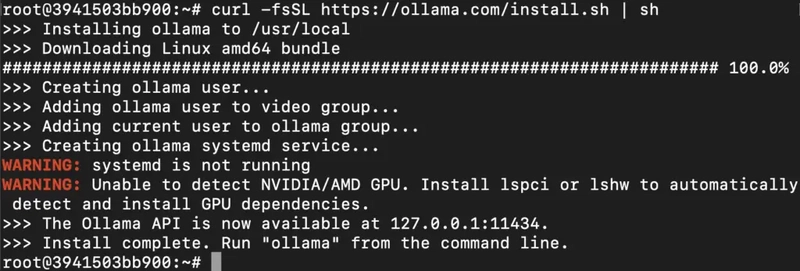
Step 9: Serve Ollama
Run the following command to host the Ollama so that it can be accessed and utilized efficiently:
OLLAMA_HOST=0.0.0.0:11434 ollama serve

Step 10: Download Void Editor
“Open Google or any web browser, type ‘Void Editor’, visit the official website, and click the ‘Download Void’ button to download it.”

Step 11: Open Void Editor
Once the download is complete, open the Void Editor app from your Applications folder or Start Menu. It should launch with a clean, minimal interface ready for setup.

Step 12: Choose Your AI Provider
Void Editor supports multiple AI providers — both free and paid — along with local and cloud options. You’ll see a dropdown or setup panel where you can choose from the following categories:
If you want to test things out without paying anything, Void supports:
- Gemini (by Google) – Just connect with your Google account.
- OpenRouter – A free gateway to access a bunch of open models.
These are great for casual usage or quick experiments.
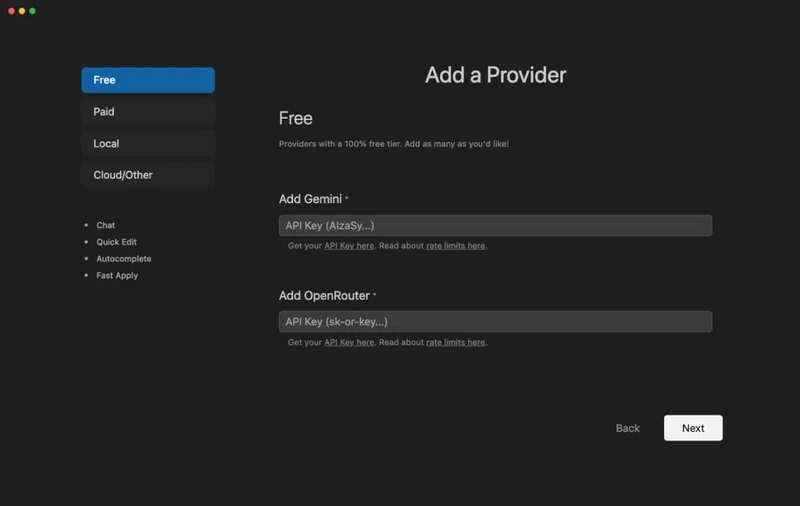
Step 13: Paid Providers
Need access to premium models? Under the paid section, you’ll find:
- OpenAI (like GPT-4, GPT-4o, etc.)
- Anthropic (Claude models)
- DeepSeek (powerful reasoning models)
Just plug in your API keys and you’re good to go.

Step 14: Local Model Options
Prefer running models entirely on your machine? Void supports:
- Ollama – Perfect for local LLMs, easy to install.
- vLLM – For more advanced and high-performance local setups.
Ideal for developers who care about privacy and performance.
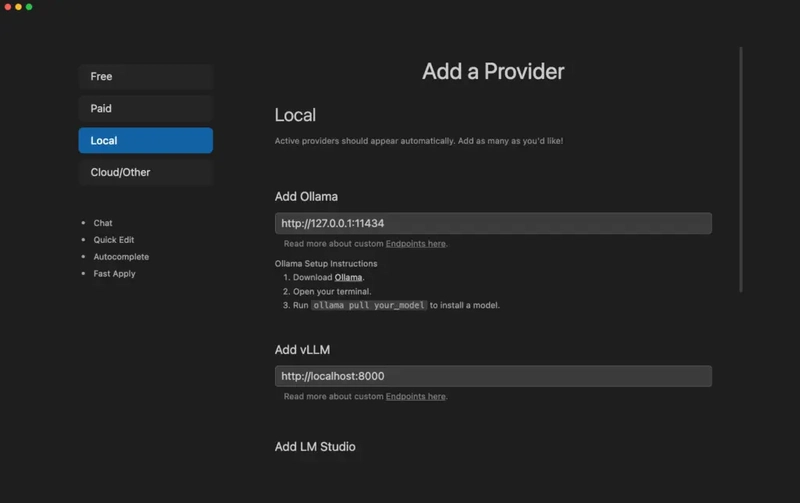
Step 15: Cloud and Other Providers
For teams or enterprise setups, Void also supports:
- Google Vertex AI
- LiteLLM
- Microsoft Azure
- And many other cloud-based options
These are typically used for scaling up or integrating into larger workflows.

Step 16: Set Up SSH Port Forwarding (For Remote Models Like Ollama on a GPU VM)
If you’re running a model like Ollama on a remote GPU Virtual Machine (e.g. via NodeShift, AWS, or your own server), you’ll need to port forward the Ollama server to your local machine so Void Editor can connect to it.
Here’s how to do it:
Example (Mac/Linux Terminal):
ssh -L 11434:localhost:11434 root@<your-vm-ip> -p <your-ssh-port>
Once connected, your local machine will treat http://localhost:11434 as if Ollama is running locally.
- Replace with your VM’s IP address
- Replace with the custom port (e.g. 26031)
### On Windows:
Use a tool like PuTTY or ssh from WSL/PowerShell with similar port forwarding.

If you’re running large language models (like Llama 3, DeepSeek, or Qwen) on a remote GPU Virtual Machine, you’ll want Void Editor on your local machine to talk to that remote Ollama instance.
But since the model is running on the VM — not on your laptop — we need to bridge the gap.
That’s where SSH port forwarding comes in.
Why use a GPU VM?
Large models require serious compute power. Your laptop might struggle or overheat trying to run them. So we spin up a GPU-powered VM in the cloud — it gives us:
- Faster responses
- Support for large models (7B, 13B, even 70B!)
- More RAM + VRAM for smoother inference
Step 17: Go with the Local Option (Using Ollama)
For this setup, we’re choosing the Local Provider route — specifically using Ollama running on a GPU Virtual Machine. This gives us:
- Fast response time
- Ability to run large models like Llama 3, DeepSeek, or Qwen
- Complete control, privacy, and offline capability
But since the model is running on a remote GPU VM, we’ll bridge your local Void Editor to that remote Ollama instance using SSH port forwarding.
Why use a GPU VM for local Ollama?
Your laptop might not have the horsepower to run big models smoothly. That’s why we spin up a GPU-powered Virtual Machine (like with an A100 or A6000) — it handles the heavy lifting, while you use Void locally with zero lag.
Head to the provider setup screen inside Void, select Ollama, and set the endpoint as:
http://localhost:11434
Done.
Your Void Editor is now connected to a powerful Ollama backend running remotely — and you’re ready to build, test, and explore with full-speed local inference.
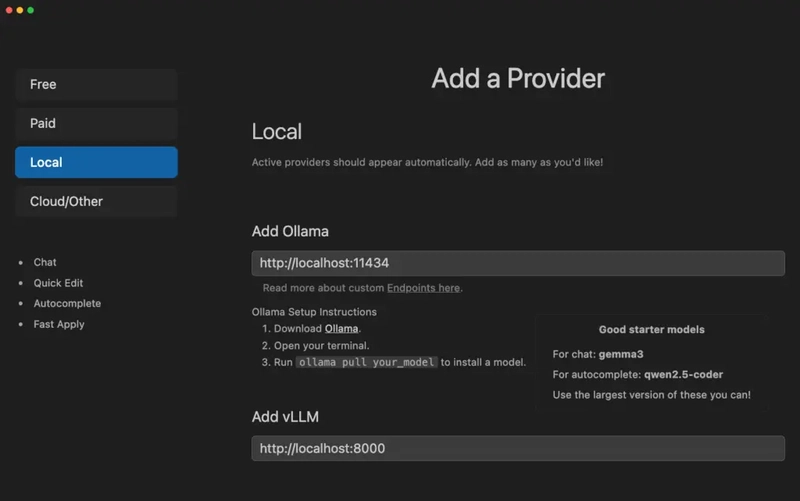
Step 18: Run Your First Models in Ollama (Devstral + Gemma 3)
Now that Void Editor is connected to Ollama via http://localhost:11434, let’s run our first models.
We’ll use two powerful open-source models:
Devstral by Mistral AI
A brand new model purpose-built for coding agents. Devstral isn’t just about code completion — it’s designed to handle real-world software engineering tasks, like resolving GitHub issues and working inside codebases.
To run it on Ollama:
ollama run devstral
Run this command on your GPU Virtual Machine, not your Mac.
Built by Mistral AI in collaboration with All Hands AI, Devstral is optimized for local use (even on a Mac with 32GB RAM or a single RTX 4090) and is fully open under the Apache 2.0 license.
If you want to dive deeper into Devstral, we’ve got a full step-by-step guide here:
Link: https://nodeshift.com/blog/a-step-by-step-to-install-devstral-mistrals-open-source-coding-agent
Gemma 3:1B by Google
Another great lightweight model you can try locally is Gemma 3, specifically the 1B variant — perfect for fast inference and lower memory usage.
Run it with:
ollama run gemma3:1b
Again, run this command on your GPU Virtual Machine.
This is a solid pick for fast testing, multi-language reasoning, and creative coding tasks — without needing a huge GPU.
You can switch between models anytime by running a different ollama run command in the background. Once it’s active, Void Editor will automatically detect and use the running model.

Step 19: Check Available Models via curl (From Your Mac)
Once your Ollama backend is running on the remote GPU VM and connected to your Mac via SSH port forwarding, you can use a simple curl command from your local machine to check which models are currently available.
First, Pull the Models (like Devstral or Gemma 3)
Before you can list anything, you’ll need to pull the models you plan to use. For example:
ollama pull devstral
ollama pull gemma3:1b
These commands run on the VM and download the models for Ollama to use.
Then, Run This Command on Your Mac:
curl http://localhost:11434/api/tags
This command connects to your forwarded Ollama server and shows a list of all the models you’ve pulled so far. It gives you a response like:
{
"models": [
{ "name": "devstral" },
{ "name": "gemma3:1b" }
]
}
Note: This command runs on your Mac, not on the VM — because we’ve already port-forwarded localhost:11434 to the remote GPU VM where Ollama is active.
So in short:
- Ollama is running remotely on a GPU VM
- You’ve connected it to your Mac via SSH
- And now you can check, query, and chat with models — all from your local editor

Step 20: View Available Models Inside Void Editor
Once your models (like devstral or gemma3:1b) are running in the background via Ollama on your GPU VM — and the port forwarding is active — Void Editor will automatically detect them.
Where to Find Them?
Head to the “Models” section inside Void Editor.
You’ll see a list of all available models that Ollama is currently serving.
Models like devstral, gemma3:1b, or any other you’ve pulled and started will show up here — ready to chat, code, or assist you inside the editor.
No need for any extra configuration — Void listens to http://localhost:11434, detects the models, and makes them available in the dropdown or sidebar automatically.
You’re now all set to write, test, and build using real local models inside Void — powered by your GPU VM!
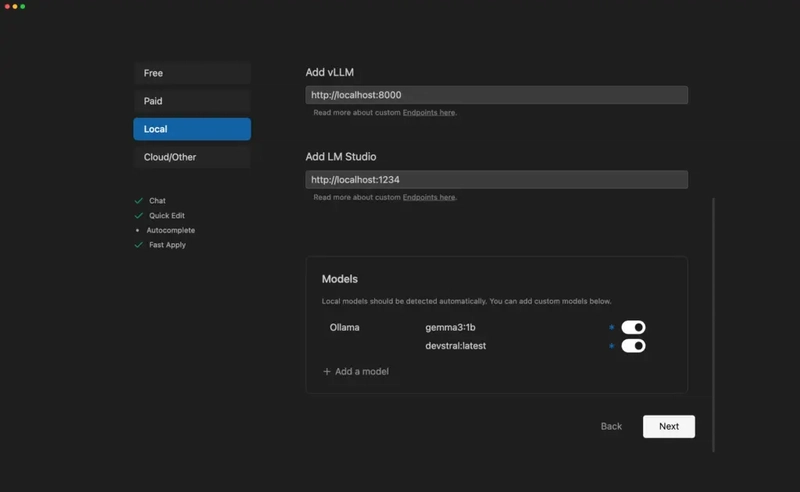

Step 21: Select a Model and Start Running Prompts
You’re almost there — now it’s time to put everything into action!
How to Use:
- Go to the Models section inside Void Editor.
- Select the model you want to use (e.g., devstral, gemma3:1b, etc.).
- Jump into any file or open a new tab.
- Use the built-in chat panel or prompt bar to ask questions, get suggestions, or generate code.
For example:
“How do I set up a Node.js server?”
“Refactor this function to use async/await.”
“Write a Python script to scrape a webpage.”
Whatever your task — Void + Ollama + your remote GPU model is now fully connected and ready to respond.
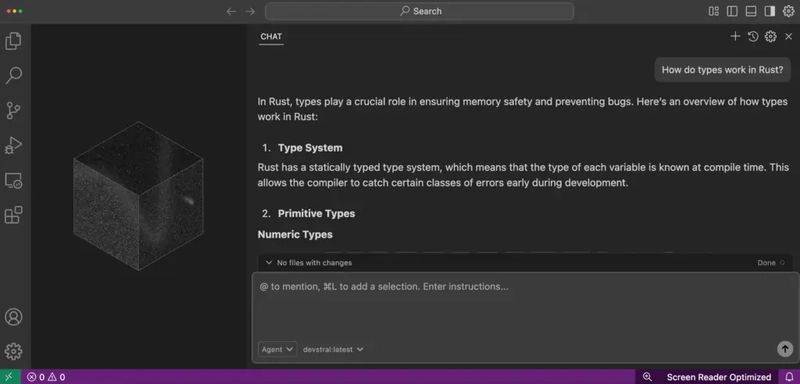



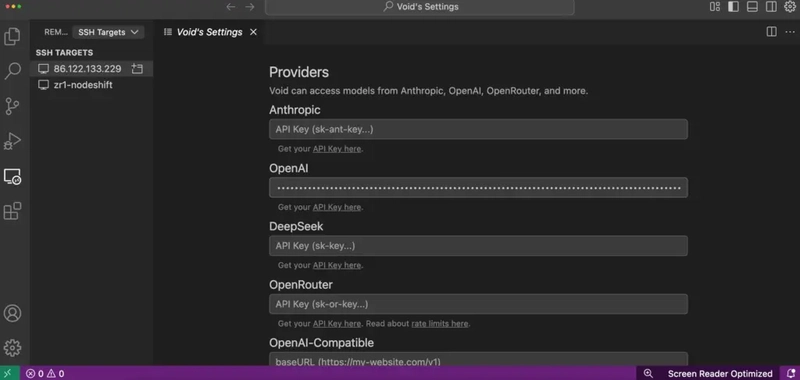
Step 22: Use a Paid Provider (Like OpenAI) by Adding Your API Key
If you prefer to use OpenAI’s models (like GPT-4 or GPT-4o), Void Editor also supports that — all you need is your OpenAI API key.
How to Set It Up:
- Open Void Editor
- Go to the Settings panel
- Navigate to the Providers or API Keys section
- Choose OpenAI from the list
- Paste your OpenAI API key in the input field
Your key stays local and is only used within the editor — privacy is respected.
 Once added, you can start using OpenAI’s models alongside your local ones. The same prompt bar and model selection flow applies — just choose OpenAI from the model menu and start coding, chatting, or writing.
Once added, you can start using OpenAI’s models alongside your local ones. The same prompt bar and model selection flow applies — just choose OpenAI from the model menu and start coding, chatting, or writing.
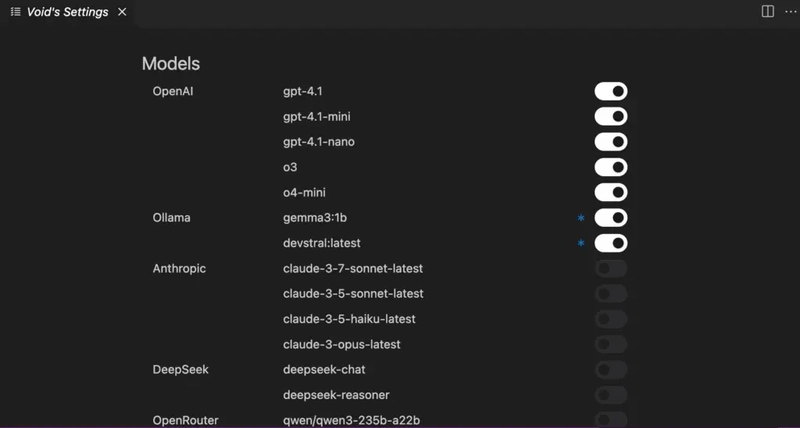

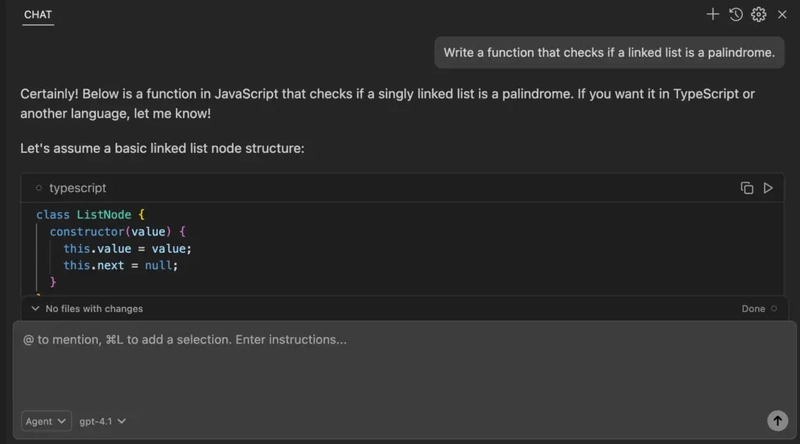
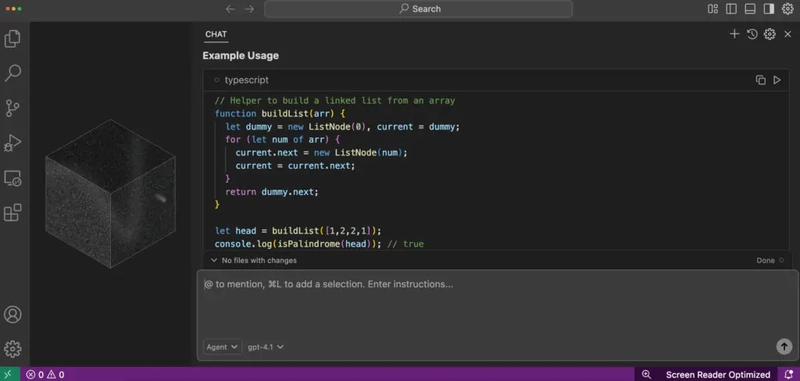
Step 23: Select OpenAI Model and Run Prompts
Now that your OpenAI API key is added in Void Editor, it’s time to put it to use.
How to Use:
- Head to the Models panel or dropdown inside Void.
- From the provider list, select OpenAI.
- Choose the model you want — like gpt-4, gpt-4o, or gpt-3.5-turbo.
- Open any file or tab and start typing your question or prompt.
For example:
“Explain what this Python function does.”
“Generate TypeScript types from this JSON.”
“Write unit tests for this function.”
The response will come directly from OpenAI’s API — integrated neatly into your Void workflow.
Whether you’re coding, debugging, or brainstorming — it just works.
Conclusion
And that’s it — you’ve now connected Void Editor to powerful local and cloud-based models using Ollama on a GPU Virtual Machine. Whether you’re running Mistral’s Devstral for real-world coding or tapping into OpenAI’s GPT-4 for rapid prompts, your setup is now fast, private, and fully in your control.
From deploying your VM to writing your first prompt — you’ve built a powerful AI coding environment, right from your own machine.



Top comments (0)