
In this series, I tested multiple MongoDB emulations on top of SQL databases, and all failed to be compatible with a simple query like listing the last orders for one product in one country:
db.orders.find(
{
country_id: 1,
order_details: { $elemMatch: { product_id: 15 } }
} ).sort({
created_at: -1
}).limit(10)
Those emulations are syntax-compatible, but not behavior-compatible when it comes to performance and scalability. With MongoDB, such query finds immediately the ten documents from the following index:
db.orders.createIndex({
"country_id": 1,
"order_details.product_id": 1,
"created_at": -1
});
It is simple: you index for the equality predicates, on country and product, and add the creation date to get the keys ordered. That's how you guarantee predictable performance in OLTP: the response time depends on the result, not on the size of the collection.
I tried the same on Google Firestore. Note that the simple find().sort().limit() syntax was not accepted by the Firestore Studio Editor, so I've run the equivalent aggregation pipeline:
db.orders.aggregate([
{
$match: {
country_id: 1,
order_details: {
$elemMatch: { product_id: 15 }
}
}
},
{
$sort: { created_at: -1 }
},
{
$limit: 10
},
])
Without an index, such query does a full collection scan, sorts all documents, and discard all except the first ten:
Billing Metrics:
read units: 0
Execution Metrics:
results returned: 0
request peak memory usage: 4.00 KiB (4,096 B)
entity row scanned: 0
Tree:
• Drop
| fields to drop: [__$3__]
| records returned: 0
| total latency: 3.00 ms
|
└── • Drop
| fields to drop: [__$6__, __$7__]
| records returned: 0
| total latency: 2.98 ms
|
└── • MajorSort
| fields: [__$6__ DESC]
| limit: 10
| peak memory usage: 4.00 KiB (4,096 B)
| records returned: 0
| total latency: 2.98 ms
|
└── • Extend
| expressions: [array_offset(__$7__, 0L) AS __$6__]
| records returned: 0
| total latency: 2.89 ms
|
└── • Extend
| expressions: [sortPaths([created_at DESC]) AS __$7__]
| records returned: 0
| total latency: 2.87 ms
|
└── • Drop
| fields to drop: [__key__, __row_id__]
| records returned: 0
| total latency: 2.87 ms
|
└── • Extend
| expressions: [_id(__name__) AS __id__]
| records returned: 0
| total latency: 2.87 ms
|
└── • Filter
| expression: ($eq(country_id, 1) AND $eq(order_details, 15))
| records returned: 0
| total latency: 2.86 ms
|
└── • TableScan
order: STABLE
properties: * - { __create_time__, __update_time__ }
source: **/orders
records returned: 0
records scanned: 0
total latency: 2.84 ms
I've run an empty collection solely to examine the execution plan's shape and understand its scalability.
I attempted to create the index using mongosh, because Firestore provides protocol compatibility, but Google Cloud requires a credit card even for the free trial, which I did not accept. As a result, billing is not enabled and I can't use it:
firestore> db.orders.createIndex(
{ "country_id": 1, "order_details .product_id": 1, "created_at": -1 }
);
MongoServerError[PermissionDenied]: Request is prohibited because billing is not enabled.
firestore>
No problem, I was able to create the index from the console:

It was created after a few minutes:
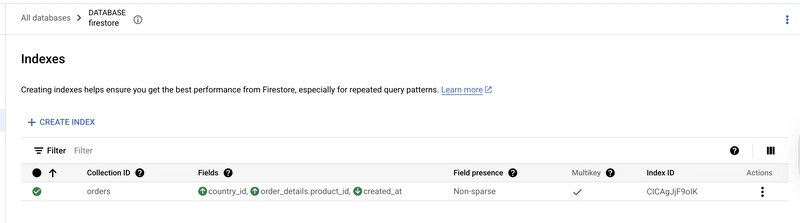
I've run my query again and here is the execution plan (called EXPLANATION in Google Firestore):
Billing Metrics:
read units: 0
Execution Metrics:
results returned: 0
request peak memory usage: 12.00 KiB (12,288 B)
entity row scanned: 0
index row scanned: 0
Tree:
• Drop
| fields to drop: [__$3__]
| records returned: 0
| total latency: 2.04 s (2,040 ms)
|
└── • Drop
| fields to drop: [__$8__, __$9__]
| records returned: 0
| total latency: 2.04 s (2,040 ms)
|
└── • MajorSort
| fields: [__$8__ DESC]
| limit: 10
| peak memory usage: 4.00 KiB (4,096 B)
| records returned: 0
| total latency: 2.04 s (2,040 ms)
|
└── • Extend
| expressions: [array_offset(__$9__, 0L) AS __$8__]
| records returned: 0
| total latency: 2.04 s (2,040 ms)
|
└── • Extend
| expressions: [sortPaths([created_at DESC]) AS __$9__]
| records returned: 0
| total latency: 2.04 s (2,040 ms)
|
└── • Drop
| fields to drop: [__key__, __row_id__]
| records returned: 0
| total latency: 2.04 s (2,040 ms)
|
└── • Extend
| expressions: [_id(__name__) AS __id__]
| records returned: 0
| total latency: 2.04 s (2,040 ms)
|
└── • Filter
| expression: $eq(order_details, 15)
| records returned: 0
| total latency: 2.04 s (2,040 ms)
|
└── • TableAccess
| order: PRESERVE_INPUT_ORDER
| properties: * - { __create_time__, __update_time__ }
| peak memory usage: 4.00 KiB (4,096 B)
| records returned: 0
| total latency: 2.04 s (2,040 ms)
|
└── • UniqueScan
index: **/orders (country_id ASC, order_details.product_id ASC, created_at DESC)@[id = CICAgJjF9oIK]
keys: [country_id ASC, __$5__ ASC, created_at DESC, __key__ ASC]
properties: Selection { __key__ }
ranges: /
|----[1]
records returned: 0
records scanned: 0
total latency: 2.04 s (2,038 ms)
The index was used to scan a range (ranges: / |----[1]) for the "country_id" filter, apparently preserving some order (order: PRESERVE_INPUT_ORDER). This could be beneficial for pagination queries, allowing it to stop when the result limit is reached.
However, the product filter ($eq(order_details, 15)) is applied after fetching documents, resulting in unnecessary reads for a filter that was not covered by the index.
Next, projections are performed to include the "id" and remove the "rowid". It appears the preserved order does not relate to the key as expected for pagination, since some computation occurs to determine the sorting field (sortPaths([created_at DESC])).
Ultimately, a sort is performed on this calculated field (fields: [__$8__ DESC]). This execution plan reads all orders from a country before being able to return the ten ones expected by the result. This is not scalable.
I ran this on an empty collection, and the table scan took two seconds (total latency: 2,038 ms). Given this result, adding data to test for larger workloads is unnecessary. The issue lies not in quantity but in quality of the compatibility, limited to very simple key-value queries, lacking the advantages of MongoDB’s flexible schema document model and multi-key index performance.
When creating the index, I checked 'multi-key' because contrary to MongoDB, it's not the same index that can be created on scalar and arrays. Let's try a non multi-key one - even if it doesn't make sense as to goal is to have multiple products per order:
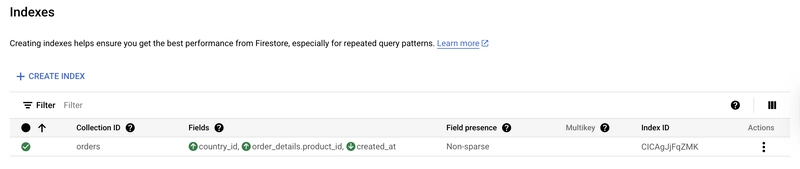
The execution plan is similar except that it shows a SequentialScan on the index instead of UniqueScan:
Billing Metrics:
read units: 0
Execution Metrics:
results returned: 0
request peak memory usage: 8.00 KiB (8,192 B)
entity row scanned: 0
index row scanned: 0
Tree:
• Drop
| fields to drop: [__$3__]
| records returned: 0
| total latency: 20.36 ms
|
└── • Drop
| fields to drop: [__$8__, __$9__]
| records returned: 0
| total latency: 20.35 ms
|
└── • MajorSort
| fields: [__$8__ DESC]
| limit: 10
| peak memory usage: 4.00 KiB (4,096 B)
| records returned: 0
| total latency: 20.35 ms
|
└── • Extend
| expressions: [array_offset(__$9__, 0L) AS __$8__]
| records returned: 0
| total latency: 20.29 ms
|
└── • Extend
| expressions: [sortPaths([created_at DESC]) AS __$9__]
| records returned: 0
| total latency: 20.27 ms
|
└── • Drop
| fields to drop: [__key__, __row_id__]
| records returned: 0
| total latency: 20.27 ms
|
└── • Extend
| expressions: [_id(__name__) AS __id__]
| records returned: 0
| total latency: 20.26 ms
|
└── • Filter
| expression: $eq(order_details, 15)
| records returned: 0
| total latency: 20.26 ms
|
└── • TableAccess
| order: PRESERVE_INPUT_ORDER
| properties: * - { __create_time__, __update_time__ }
| peak memory usage: 4.00 KiB (4,096 B)
| records returned: 0
| total latency: 20.25 ms
|
└── • SequentialScan
index: **/orders (country_id ASC, order_details.product_id ASC, created_at DESC)@[id = CICAgJjFqZMK]
key ordering length: 4
keys: [country_id ASC, __$5__ ASC, created_at DESC, __key__ ASC]
properties: Selection { __key__ }
ranges: /
|----[1]
records returned: 0
records scanned: 0
total latency: 20.16 ms
My interpretation is that, in all cases, Firestore with MongoDB compatibility cannot use indexes to cover a sort. Either it is multi-key, and entries have to be deduplicated, or it is single key, but the index only covers the filtering on the country, not the product or the creation date.
In summary, another database claims compatibility with MongoDB by using its protocol and offering a similar API for storing documents. This reinforces MongoDB's status as the de facto standard for document databases. However, as discussed in previous posts, storing JSON in a relational database does not convert it into a document database, and similarly, storing JSON in a key-value data store does not replace MongoDB. If your MongoDB application runs on one of those emulations, you are likely using it as a key-value datastore without using the full potential of a general-purpose document database.


Top comments (0)