
Hey Dev.to community! 👋
Ever found your trusty relational database groaning under the weight of modern application demands? You're not alone. Scaling, managing schema changes, and ensuring consistent, low-latency performance for today's global, high-traffic applications can feel like an uphill battle with traditional systems.
Enter Amazon DynamoDB, AWS's flagship NoSQL key-value and document database. It's built from the ground up for the cloud, designed for virtually limitless scale, and powers some of the world's largest applications (think parts of Amazon.com itself!). If you're building serverless applications, microservices, gaming backends, or anything requiring predictable high performance, DynamoDB is a service you need to know.
In this comprehensive guide, I'll dissect DynamoDB's core architecture, explore its powerful features, and, crucially, dive deep into securing your valuable data. Whether you're a DynamoDB newbie wondering where to start or an experienced developer looking to solidify your understanding and pick up some new tricks, you'll walk away with actionable insights. Let's unlock its potential together!
📜 Table of Contents
- Why Amazon DynamoDB Matters in 2025
- Understanding DynamoDB in Simple Terms: The Infinite Filing Cabinet
- Deep Dive: DynamoDB Core Components
- Fortifying Your Data: DynamoDB Security Deep Dive
- Real-World Use Case: Building a Scalable URL Shortener
- Common Pitfalls & Best Practices to Avoid Them
- Pro Tips & What's Next for DynamoDB
- Conclusion & Your Next Steps
- Let's Connect!
🚀 Why Amazon DynamoDB Matters in 2025
In today's cloud-native world, applications demand speed, reliability, and scalability – often at a global level. DynamoDB is engineered precisely for these needs.
- Massive Scalability: DynamoDB can handle more than 10 trillion requests per day and support peaks of more than 20 million requests per second. This is the kind of scale that powers Amazon Prime Day, one of the largest shopping events globally.
- Serverless Champion: It's a fully managed service. No servers to patch, no software to install or maintain. This makes it a perfect companion for serverless architectures using AWS Lambda.
- Consistent Performance: DynamoDB delivers single-digit millisecond latency, regardless of table size or request volume. This is crucial for user-facing applications where responsiveness is key.
- Flexible Data Model: Being a NoSQL database, it supports key-value and document data models, allowing for flexible schema design that can evolve with your application.
- Growing Ecosystem: AWS continues to invest heavily in DynamoDB, regularly announcing new features and integrations that enhance its capabilities, like improved import/export options and deeper analytics integrations.
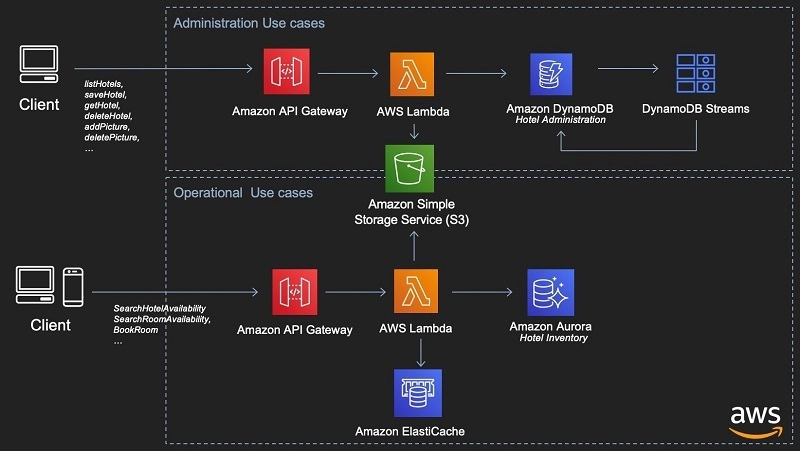
Caption: DynamoDB's role in the modern AWS serverless application stack.
Simply put, if you're building for performance and scale on AWS, DynamoDB is almost certainly on your radar, or it should be!
🗄️ Understanding DynamoDB in Simple Terms: The Infinite Filing Cabinet
Imagine a massive, digital filing cabinet system that's practically infinite in size.
- Tables are like individual filing cabinets. Each cabinet is dedicated to a specific type of information (e.g., "Users," "Products," "Orders").
- Items are like folders within a cabinet. Each folder represents a single record (e.g., a specific user, a particular product).
- Attributes are like pieces of paper (or fields) inside a folder. These contain the actual data points for that item (e.g.,
username,email,productName,price). - The Primary Key is your unique filing system ID. It tells DynamoDB exactly where to find a specific folder (item) instantly, without searching through the entire cabinet.
The magic is that this "filing cabinet system" automatically expands as you add more data, and it can retrieve any folder almost instantly, no matter how many folders it contains. You don't worry about running out of space or how the filing is organized behind the scenes – AWS handles all of that complexity.
🛠️ Deep Dive: DynamoDB Core Components
Let's get into the nitty-gritty. Understanding these core components is fundamental to effectively using DynamoDB.
Tables, Items, and Attributes
- Table: The top-level container for your data. You define a table name and its primary key.
- Item: A collection of attributes. Each item is uniquely identified by its primary key. Think of an item as a row in a traditional database, but with more flexibility in its structure. Items can have varying attributes.
-
Attributes: The individual data elements that make up an item. Each attribute has a name and a value. DynamoDB supports various data types:
- Scalar Types: String, Number, Binary, Boolean, Null.
- Document Types: List (ordered collection), Map (unordered collection of key-value pairs).
- Set Types: String Set, Number Set, Binary Set (unordered collection of unique scalar values).
// Example of an Item in a 'Users' table { "userId": "user123", // String (Primary Key) "username": "awsninja", "email": "ninja@example.com", "followers": 10000, // Number "interests": ["aws", "serverless", "devops"], // List of Strings "profile": { // Map "bio": "Cloud enthusiast", "location": "The Cloud" }, "subscribedTopics": {"S", "dynamodb", "lambda"} // String Set }
Primary Keys: The Heart of Your Data Model
The primary key uniquely identifies each item in a table. DynamoDB supports two types:
-
Partition Key (Simple Primary Key):
- A single attribute.
- DynamoDB uses the partition key's value as input to an internal hash function. The output determines the partition (physical storage internal to DynamoDB) where the item is stored.
- Crucial for distributing data evenly. Choose an attribute with high cardinality (many unique values).
- Example:
userIdfor aUserstable,orderIdfor anOrderstable.
-
Partition Key and Sort Key (Composite Primary Key):
- Two attributes: a partition key and a sort key.
- All items with the same partition key are stored together, physically sorted by the sort key value.
- This allows you to efficiently query for all items with a specific partition key, optionally filtering or retrieving a range based on the sort key.
- Example: In a
GameScorestable,userId(partition key) andtimestamp(sort key) would let you get all scores for a user, sorted by time.
# AWS CLI: Creating a table with a simple primary key aws dynamodb create-table \ --table-name Users \ --attribute-definitions AttributeName=userId,AttributeType=S \ --key-schema AttributeName=userId,KeyType=HASH \ --provisioned-throughput ReadCapacityUnits=5,WriteCapacityUnits=5 # AWS CLI: Creating a table with a composite primary key aws dynamodb create-table \ --table-name Orders \ --attribute-definitions \ AttributeName=customerId,AttributeType=S \ AttributeName=orderDate,AttributeType=S \ --key-schema \ AttributeName=customerId,KeyType=HASH \ AttributeName=orderDate,KeyType=RANGE \ --provisioned-throughput ReadCapacityUnits=5,WriteCapacityUnits=5Choosing your primary key is one of the most critical design decisions in DynamoDB. It dictates your primary access patterns.
Throughput Capacity: Provisioned vs. On-Demand
DynamoDB offers two capacity modes for reads and writes:
-
Provisioned Mode:
- You specify the number of Read Capacity Units (RCUs) and Write Capacity Units (WCUs) your application requires.
- 1 RCU = one strongly consistent read per second, or two eventually consistent reads per second, for items up to 4 KB.
- 1 WCU = one write per second for items up to 1 KB.
- Best for applications with predictable traffic. You can use auto-scaling to adjust capacity.
- Cost-effective if you can predict your workload.
-
On-Demand Mode:
- You pay per request for reads and writes. No need to specify capacity.
- DynamoDB instantly accommodates your workload as it ramps up or down.
- Ideal for applications with unknown, spiky, or unpredictable traffic patterns.
- Simpler to manage, but can be more expensive for sustained high-throughput workloads compared to well-optimized provisioned capacity.
You can switch between these modes once every 24 hours.
Secondary Indexes: Querying Flexibility
While the primary key provides your main access pattern, you often need to query data using other attributes. Secondary indexes enable this without performing inefficient table scans.
-
Local Secondary Index (LSI):
- Same partition key as the base table, but a different sort key.
- "Local" because data in an LSI is co-located in the same partition as the base table data for that partition key.
- You can choose which attributes from the base table are projected (copied) into the LSI.
- Offers strong or eventual consistency for reads.
- Must be created when the table is created. Limited to 5 LSIs per table.
-
Global Secondary Index (GSI):
- Different partition key and an optional different sort key from the base table.
- "Global" because it spans all data across all partitions of the base table. It's essentially a new "copy" of your table organized by different keys.
- Queries on GSIs are eventually consistent.
- Can be created or deleted at any time. You provision RCU/WCU for GSIs independently of the base table.
- Up to 20 GSIs per table (default limit, can be increased).
# Boto3 Python: Querying using a GSI import boto3 dynamodb = boto3.client('dynamodb') response = dynamodb.query( TableName='Users', IndexName='EmailIndex', # Assuming a GSI on the 'email' attribute KeyConditionExpression='email = :email_val', ExpressionAttributeValues={ ':email_val': {'S': 'user@example.com'} } ) items = response.get('Items', []) print(f"Found items: {items}")
DynamoDB Streams: Capturing Changes
DynamoDB Streams capture a time-ordered sequence of item-level modifications (create, update, delete) in any DynamoDB table.
- Each stream record contains information about the data modification.
- You can trigger AWS Lambda functions from a stream to react to data changes in real-time.
- Use cases: cross-region replication, data aggregation, audit trails, notifications.
🛡️ Fortifying Your Data: DynamoDB Security Deep Dive
Security is paramount. DynamoDB offers a robust set of features to protect your data. AWS operates on a shared responsibility model: AWS secures the underlying infrastructure, and you secure your data in the cloud.
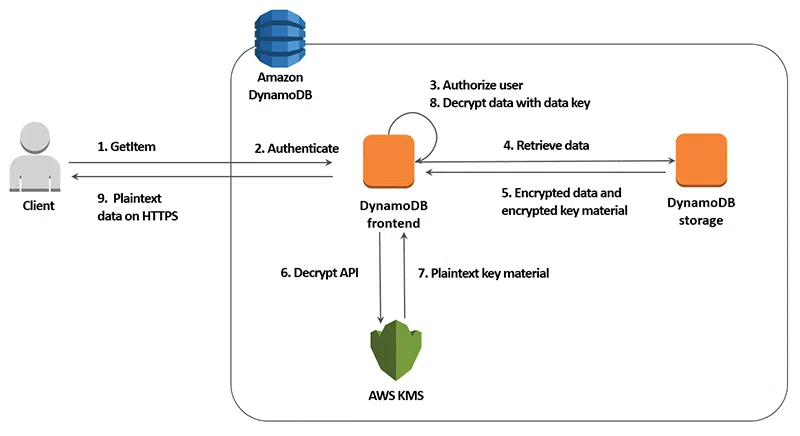
Caption: Layers of DynamoDB Security: IAM, Encryption, Network, Monitoring.
Identity and Access Management (IAM)
IAM is the cornerstone of AWS security. For DynamoDB, you use IAM to control who can access your tables and what actions they can perform.
- IAM Users, Groups, and Roles: Grant permissions to identities. Use roles for applications running on EC2, Lambda, ECS, etc., to avoid hardcoding credentials.
- IAM Policies: JSON documents that define permissions.
- Table-level permissions:
dynamodb:CreateTable,dynamodb:DescribeTable,dynamodb:PutItem,dynamodb:GetItem,dynamodb:Query,dynamodb:Scan,dynamodb:DeleteItem, etc. - Fine-Grained Access Control (FGAC):
- Condition Keys: Restrict access based on item attributes (e.g., allow a user to only access items where
userIdmatches their ID). - Leading Keys: Restrict access to items based on the partition key value.
- Attribute-level access control: (More complex, often involves conditions on specific attributes, sometimes managed by your application logic or API Gateway authorizers).
- Condition Keys: Restrict access based on item attributes (e.g., allow a user to only access items where
- Table-level permissions:
- Principle of Least Privilege: Always grant only the minimum permissions necessary.
// Example IAM Policy: Allow Lambda to read/write to a specific DynamoDB table
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DynamoDBAccess",
"Effect": "Allow",
"Action": [
"dynamodb:PutItem",
"dynamodb:GetItem",
"dynamodb:UpdateItem",
"dynamodb:DeleteItem",
"dynamodb:Query"
],
"Resource": "arn:aws:dynamodb:us-east-1:123456789012:table/MyApplicationTable"
}
]
}
Encryption: At Rest and In Transit
- Encryption at Rest:
- DynamoDB encrypts all data at rest by default using AWS-owned keys. There's no performance impact and no action needed from you.
- For enhanced control, you can choose:
- AWS Key Management Service (KMS) - AWS managed key (aws/dynamodb): Free, managed by AWS.
- AWS KMS - Customer managed key (CMK): You create and manage the key in KMS. Provides more control, auditability (via CloudTrail for key usage), and the ability to manage key rotation. This incurs KMS costs.
- Encryption in Transit:
- All communication with the DynamoDB service endpoint uses HTTPS/TLS, encrypting data in transit.
Network Security: VPC Endpoints
If your applications accessing DynamoDB run within a Virtual Private Cloud (VPC), you can use VPC Endpoints for DynamoDB.
- Gateway Endpoints: Allows instances in your VPC to access DynamoDB without traversing the public internet. Traffic stays within the AWS network. This is a highly recommended best practice for security and can sometimes offer better network performance.
- Interface Endpoints (PrivateLink): Provide private connectivity to DynamoDB using an Elastic Network Interface (ENI) in your VPC with private IP addresses. Useful for on-premises access via Direct Connect or VPN.
Auditing and Monitoring
- AWS CloudTrail: Logs all API calls made to DynamoDB (control plane and data plane actions). Essential for security analysis, resource change tracking, and compliance auditing.
- Amazon CloudWatch:
- Metrics: DynamoDB publishes many metrics like
ConsumedReadCapacityUnits,ConsumedWriteCapacityUnits,ThrottledRequests,SystemErrors,UserErrors,Latency. Set alarms on these! - Logs: You can enable CloudWatch Logs for DynamoDB Streams data.
- Contributor Insights: Helps identify the most frequently accessed keys and items causing traffic imbalances (hot keys/items). This is invaluable for troubleshooting performance issues and optimizing table design.
- Metrics: DynamoDB publishes many metrics like
Backup and Recovery
- On-Demand Backups: Create full backups of your tables at any time. Backups are cataloged, discoverable, and can be restored to a new table. Does not affect table performance or availability.
- Point-in-Time Recovery (PITR):
- Continuously backs up your table data.
- Allows you to restore your table to any point in time during the last 35 days, down to the second.
- Helps protect against accidental writes or deletes. Enable this for all production tables!
🌐 Real-World Use Case: Building a Scalable URL Shortener
Let's illustrate with a common example: a URL shortener service.
Requirements:
- Users submit a long URL and get a short ID.
- When a user accesses
https://short.url/{shortId}, they are redirected to the long URL. - Track click counts (optional).
DynamoDB Design:
- Table Name:
UrlMappings - Primary Key:
shortId(String, Partition Key). This allows direct lookup for redirection. - Attributes:
-
shortId(S): e.g., "aBcDeF" -
longUrl(S): The original long URL. -
createdAt(S): ISO 8601 timestamp. -
clickCount(N): Number of clicks (use atomic counters for updates).
-
- Optional GSI for duplicate checks (if needed):
- Index Name:
LongUrlIndex - Partition Key:
longUrl(S) - Projected Attributes:
shortId(to find if a long URL already has a short ID).
- Index Name:
- Capacity Mode: On-Demand is a good start for unpredictable traffic.
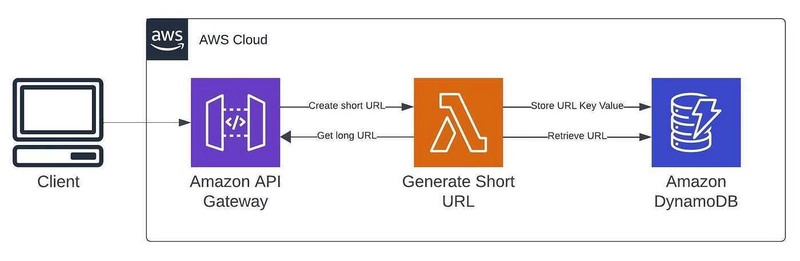
Caption: Simplified architecture for a URL shortener using API Gateway, Lambda, and DynamoDB.
Workflow Snippet (Conceptual Python/Boto3):
# --- Lambda function to create a short URL ---
import boto3
import shortuuid # For generating short IDs
import datetime
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('UrlMappings')
def create_short_url(event):
long_url = event['longUrl']
short_id = shortuuid.uuid()[:6] # Generate a short, unique ID
try:
table.put_item(
Item={
'shortId': short_id,
'longUrl': long_url,
'createdAt': datetime.datetime.utcnow().isoformat(),
'clickCount': 0
},
ConditionExpression='attribute_not_exists(shortId)' # Ensure ID is unique
)
return {'shortUrl': f'https://yourdomain.com/{short_id}'}
except Exception as e:
# Handle potential collision or other errors
print(e)
return {'error': 'Could not create short URL'}
# --- Lambda function to redirect (called by API Gateway) ---
def redirect_url(event):
short_id = event['pathParameters']['shortId']
try:
response = table.get_item(Key={'shortId': short_id})
item = response.get('Item')
if item:
# Atomically increment clickCount
table.update_item(
Key={'shortId': short_id},
UpdateExpression='SET clickCount = clickCount + :val',
ExpressionAttributeValues={':val': 1}
)
return {
'statusCode': 301,
'headers': {'Location': item['longUrl']}
}
else:
return {'statusCode': 404, 'body': 'URL not found'}
except Exception as e:
print(e)
return {'statusCode': 500, 'body': 'Server error'}
Security & Cost Notes:
- IAM Role for Lambda: The Lambda functions would need an IAM role with
dynamodb:PutItem,dynamodb:GetItem, anddynamodb:UpdateItempermissions scoped to theUrlMappingstable. - VPC Endpoint: If Lambda runs in a VPC, use a DynamoDB Gateway Endpoint.
- Cost: With On-Demand, you pay per request. For high traffic, monitor costs and consider Provisioned Capacity with Auto Scaling. TTL could be used to expire very old, unused links.
This example demonstrates how DynamoDB's key-value nature and scalability make it a great fit.
🚧 Common Pitfalls & Best Practices to Avoid Them
While powerful, DynamoDB has its learning curve. Here are common traps and how to sidestep them:
-
Pitfall: Hot Partitions.
- Problem: Uneven data access patterns where a small subset of partition keys receives a disproportionate amount of traffic, overwhelming the capacity of those partitions.
- Best Practice: Design partition keys with high cardinality. If necessary, use techniques like write sharding (adding a random suffix to partition keys) or leverage GSIs for alternative access patterns. Monitor with CloudWatch Contributor Insights.
-
Pitfall: Overusing Scans.
- Problem:
Scanoperations read every item in a table or GSI, which is inefficient and costly for large tables. - Best Practice: Design your tables and GSIs to support your query patterns using
Queryoperations, which are much more efficient as they target specific partition keys. UseScansparingly, typically for administrative tasks on small tables or during development.
- Problem:
-
Pitfall: Misunderstanding Consistency Models.
- Problem: Not realizing that reads from GSIs and default table reads are eventually consistent. This can lead to stale data if an immediate read follows a write.
- Best Practice: Understand the trade-offs. For reads that require absolute up-to-date data, use strongly consistent reads on the base table (doubles RCU cost). For GSIs, design your application to tolerate eventual consistency or implement read-after-write patterns with retries/delays if strong consistency is critical on GSI data.
-
Pitfall: Over/Under-provisioning Capacity (Provisioned Mode).
- Problem: Setting RCUs/WCUs too low leads to throttling and errors. Setting them too high wastes money.
- Best Practice: Monitor
Consumed*CapacityUnitsandThrottledRequestsmetrics in CloudWatch. Implement DynamoDB Auto Scaling to adjust provisioned capacity automatically based on demand. Consider On-Demand mode if workloads are highly unpredictable.
-
Pitfall: Trying to "Normalize" like SQL / Ignoring Single Table Design for Complex Cases.
- Problem: Applying relational database design principles (multiple normalized tables) directly to DynamoDB can lead to many tables and complex application-side joins, negating NoSQL benefits.
- Best Practice: For simple use cases, separate tables are fine. For complex, related data, explore Single Table Design (STD). This involves storing different but related entity types in a single table, using generic primary key attributes (e.g.,
PK,SK) and GSIs to model one-to-many and many-to-many relationships. This is an advanced topic but incredibly powerful.
-
Pitfall: Not Enabling Point-in-Time Recovery (PITR).
- Problem: Accidental data deletion or corruption occurs, and there's no way to restore to a recent state.
- Best Practice: Enable PITR on all your production tables. It's a lifesaver.
✨ Pro Tips & What's Next for DynamoDB
Elevate your DynamoDB game with these tips:
- DynamoDB Accelerator (DAX): An in-memory cache for DynamoDB. Provides microsecond read latency for read-heavy workloads. Transparently integrates with your existing DynamoDB application logic.
- Global Tables: Build fully managed, multi-region, multi-active database solutions. Data is automatically replicated across selected AWS Regions. Great for global applications requiring low-latency access and disaster recovery.
- Time To Live (TTL): Automatically delete expired items from your tables at no cost. Perfect for session data, logs, or temporary information.
- Atomic Counters: Increment or decrement numeric attributes directly without reading the item first. Useful for counters, leaderboards, etc. (e.g.,
UpdateItemwithADDaction). - Conditional Writes: Perform
PutItem,UpdateItem, orDeleteItemoperations only if certain attribute conditions are met. Prevents overwriting data or ensures idempotency. - Batch Operations (
BatchGetItem,BatchWriteItem): Retrieve or write multiple items in a single request. Reduces network latency but be mindful of individual item size and overall request limits. - Export to S3 / Import from S3: Easily export table data to Amazon S3 (e.g., for analytics with Athena or Redshift) and import data from S3 into a new DynamoDB table. This has seen significant improvements recently.
What's Next?
AWS continues to innovate with DynamoDB. Keep an eye on:
- Enhanced integrations with other AWS services (e.g., analytics, machine learning).
- More flexibility in data modeling and querying.
- Improvements in operational efficiency and cost optimization features.
- Zero-ETL integrations with services like Amazon Redshift for near real-time analytics.
Always check the AWS News Blog and re:Invent announcements for the latest!
🏁 Conclusion & Your Next Steps
Amazon DynamoDB is a powerhouse NoSQL database, purpose-built for modern, scalable, and high-performance applications. By understanding its core components—tables, items, primary keys, indexes, and capacity modes—and by diligently applying security best practices around IAM, encryption, and network controls, you can build robust and reliable systems.
Key Takeaways:
- Design for Access Patterns: Your primary key and GSI design are paramount.
- Security is Job Zero: Leverage IAM, encryption, VPC Endpoints, and monitoring.
- Choose the Right Capacity Mode: Provisioned for predictable, On-Demand for unpredictable.
- Monitor, Monitor, Monitor: CloudWatch metrics are your best friend.
- Embrace NoSQL Thinking: Don't just lift and shift relational designs.

Caption: Your learning journey with DynamoDB has just begun!
Further Learning:
- Official AWS DynamoDB Developer Guide: aws.amazon.com/dynamodb/developer-guide/
- DynamoDB Best Practices: docs.aws.amazon.com/amazondynamodb/latest/developerguide/best-practices.html
- AWS Certified Database - Specialty: Consider this certification to validate your expertise.
- Workshops & Tutorials: Check out AWS's own workshops and various online learning platforms.
💬 Let's Connect!
I hope this deep dive into Amazon DynamoDB has been valuable for you! Building a strong foundation in services like DynamoDB is key to becoming a proficient cloud professional.
- 👇 What are your biggest challenges or "aha!" moments with DynamoDB?
- 🤯 Any pro tips you'd like to share with the community?
- 🔖 Bookmark this post for future reference!
If this helped you, I'd be thrilled if you'd:
- Follow me here on Dev.to for more AWS insights, tutorials, and cloud strategy discussions.
- Leave a comment below with your thoughts, questions, or experiences!
- Connect with me on LinkedIn: LinkedIn - let's build our networks!
Thanks for reading, and happy building in the cloud!



Top comments (5)
DynamoDB just keeps getting better—2025 really stepped up its game on security and performance. Love how it now includes encryption by default, VPC support, and fine-grained access control. If you're deep in AWS, it's hard to beat for building secure, scalable apps.
Rightly said Deividas Strole!
100% agree with you.
the amount of detail here is wild, I always end up looking up one thing and then getting sucked into a whole new rabbit hole lol
I am glad you liked the post content David.
Looking to get started with AWS DynamoDB?
Here is the good start with practical example.
Some comments may only be visible to logged-in visitors. Sign in to view all comments.