
Co-authored with Josh Long, Spring Developer Advocate on the Spring team and Youtuber at YouTube.com/@coffeesoftware.
Spring AI 1.0 is now available after a significant development period influenced by rapid advancements in the AI field. Spring AI is a new project from the Spring team that gives you structured, declarative access to large language models, vector search, image generation, and more—directly from your Spring Boot apps. The release includes numerous essential new features for AI engineers.
Java and Spring are in a prime spot to jump on this whole AI wave. Tons of companies are running their stuff on Spring Boot, which makes it super easy to plug AI into what they're already doing. You can basically link up your business logic and data right to those AI models without too much hassle.
If you just want the code for this tutorial, check out our GitHub repository.

What is Spring AI?
Spring AI provides support for various AI models and technologies. Image models can generate images given text prompts. Transcription models can take audio and convert them to text. Embedding models convert arbitrary data into vectors, which are data types optimized for semantic similarity search. Chat models should be familiar! You’ve no doubt even had a brief conversation with one somewhere. Chat models are where most of the fanfare seems to be in the AI space. They're awesome. You can get them to help you correct a document or write a poem. (Just don’t ask them to tell a joke… yet.) They’re awesome but they have some issues.

(The picture shown is used with permission from the Spring AI team lead Dr. Mark Pollack)
AI models are powerful but inherently limited in a few key areas. Spring AI addresses these limitations with targeted solutions:
Chat models and system prompts: Chat models are open-ended and prone to distraction. To guide their responses, you provide a system prompt—a structured directive that sets the tone and context for all interactions.
Memory management: AI models have no inherent memory. To maintain context across interactions, you need to implement memory mechanisms that correlate past and current messages.
Tool calling: Models operate in isolated environments. However, with tool calling, you can expose specific functions that the model can invoke when necessary, allowing for multi-turn interactions without custom orchestration logic.
Data access and prompt engineering: Models don’t have access to your proprietary databases—nor would you want them to by default. Instead, you can inject context by appending relevant information to the prompt. But there’s a limit to how much data you can include.
Retrieval-augmented generation (RAG): Instead of stuffing the prompt with data, use a vector store like MongoDB Atlas to retrieve only the most relevant information. This targeted approach reduces complexity and response size, enhancing both accuracy and cost-efficiency.
Response validation: AI models can confidently produce incorrect information. Evaluation models can validate or cross-check responses to mitigate these hallucinations.
Integration and workflows with MCP: No AI system functions in isolation. With Model Context Protocol (MCP), you can connect your Spring AI applications to other MCP-enabled services, regardless of language or platform, creating structured, goal-driven workflows.
You can leverage familiar Spring Boot conventions with Spring AI’s streamlined autoconfigurations, accessible through Spring Initializr. Spring AI provides convenient Spring Boot autoconfigurations that give you the convention-over-configuration setup you’ve come to know and expect. And Spring AI supports observability with Spring Boot’s Actuator and the Micrometer project. It plays well with GraalVM and virtual threads, too, allowing you to build super fast and efficient AI applications that scale.
Integrating Spring AI with MongoDB
Whether you're new to MongoDB or already building apps with it, MongoDB offers a modern, flexible foundation for AI-driven development. As a document database, MongoDB stores data in a JSON-like format, making it a natural fit for handling unstructured and semi-structured data—like user input, chat messages, or documents.
With Atlas Vector Search, MongoDB extends this flexibility by letting you store and search vector embeddings alongside your application data—all in the same place. Vector embeddings are just numerical representations of your data. For example, a product description or support ticket might be turned into a 512-dimensional vector—a list of numbers capturing its semantic meaning. This simplifies your architecture: no need for a separate vector database, custom pipelines, or syncing between systems.
If you're using Java, the MongoDB Java Sync Driver and Spring AI make it easy to integrate semantic search and LLM-based features directly into your application.
What is retrieval-augmented generation (RAG)?
Retrieval-augmented generation is a powerful pattern for improving the quality of large language model (LLM) responses. It works by pairing a language model with a document retrieval system—like MongoDB Atlas Vector Search—to ground the model's output in real, up-to-date information.
Why use RAG? Working with LLMs alone comes with limitations:
- Outdated knowledge: LLMs are trained on static snapshots of the internet and may not know about recent developments.
- Lack of context: They can’t access your private or domain-specific data unless you provide it.
- Hallucinations: Without access to authoritative context, LLMs may generate plausible-sounding but incorrect information.
RAG addresses these gaps by introducing real-world context into the generation process:
- Ingest: Convert your internal documents or domain-specific data into vector embeddings and store them in a vector store like MongoDB Atlas.
- Retrieve: When a user asks a question, use MongoDB Atlas Vector Search to find semantically relevant documents based on the meaning of the query—not just keyword matching.
- Generate: Feed the retrieved documents to the LLM as context, so it can generate accurate, relevant responses.
This architecture is great for building chatbots, document Q&A systems, or internal assistants that can reason over your organization's knowledge, not just what the model was originally trained on.
By combining Spring AI’s APIs with MongoDB Atlas Vector Search, you can build intelligent, production-ready applications without leaving the Java ecosystem. Let’s start wiring up your first RAG-powered AI app.
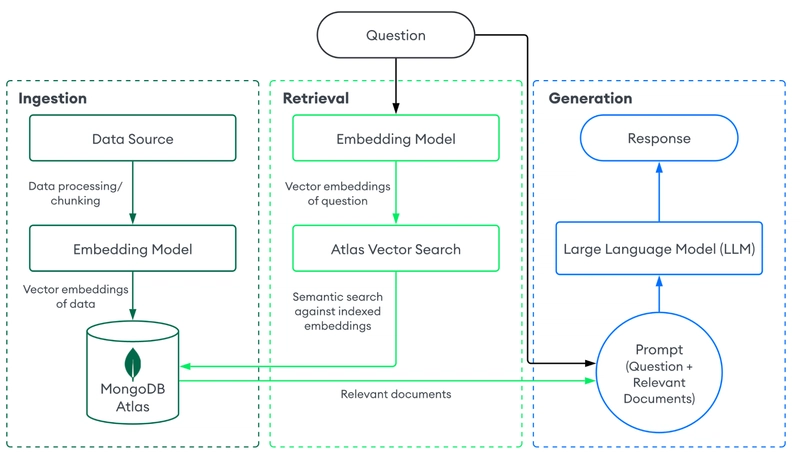
Here’s a diagram outlining how our app will work. The user sends a question to the chat endpoint. The question is embedded using our AI model, and this embedding is then used to retrieve relevant documents in our database using vector search. These documents, as well as system prompt and optional chat memory, are applied to maintain context. These documents are injected into the prompt, and the LLM generates a context-aware response, which is then returned to the user.
Building the application: Meet the dogs
We're building a fictitious dog adoption agency called Pooch Palace. It's like a shelter where you can find and adopt dogs online! And just like most shelters, people are going to want to talk to somebody, to interview the dogs. We're going to build a service to facilitate that: an assistant.
Our goal is to build an assistant to help us find the dog of (somebody's!) dream, Prancer, who is described rather hilariously as “a demonic, neurotic, man-hating, animal-hating, children-hating dog that looks like a gremlin.” This dog’s awesome. You might’ve heard about him. He went viral a few years ago when his owner was looking to find a new home for him. The ad was hysterical! Here’s the original post, in Buzzfeed News, in USA Today, and in the New York Times.
We’re going to build a simple HTTP endpoint that will use the Spring AI integration with an LLM. In this case, we’ll use Open AI, though you can use anything you’d like, including Ollama, Amazon Bedrock, Google Gemini, HuggingFace, and scores of others. It’s all supported through Spring AI to ask the AI model to help us find the dog of our dreams by analysing our question and deciding—after looking at the dogs in the shelter (and in our database)—which might be the best match for us.
Getting started: Project setup
To follow along, you’ll need Java version 24 and Maven on your machine ready to run. You’ll also need a MongoDB Atlas cluster set up (the M0 free tier will work), and an OpenAI account with an API key ready to go.
Go to Spring Initializr, create a new project with the artifact ID mongodb, and add the following dependencies:
- Web
- Actuator
- GraalVM
- Devtools
- OpenAI
- MongoDB Atlas Vector Database
We’re using Java 24 and Apache Maven, but you can adjust as needed. Download the .zip file and open it in your preferred IDE. We need to put the following properties into our application.properties:
spring.application.name=mongodb
# ai
spring.ai.openai.api-key=<YOUR_OPENAI_CREDENTIAL_HERE>
# mongodb
spring.data.mongodb.uri=<YOUR_MONGODB_ATLAS_CONNECTION_STRING_HERE>
spring.data.mongodb.database=rag
# mongodb atlas vector store
spring.ai.vectorstore.mongodb.collection-name=vector_store
spring.ai.vectorstore.mongodb.initialize-schema=true
# scale
spring.threads.virtual.enabled=true
# health
management.endpoints.web.exposure.include=*
management.endpoint.health.show-details=always
Let’s walk through some of the configuration values. The ai section defines an OpenAI credential. You can and should externalize this as an environment variable, like this: SPRING_AI_OPENAI_API_KEY. This way, you never risk accidentally checking in the credentials to your GitHub repository.
In the mongodb section, we've got the usual bread-and-butter connectivity details. Again, you’ll get this from your MongoDB Atlas account and you’d do well to externalize it into an environment variable.
Then, in the mongodb atlas vector store section, we tell MongoDB Atlas Vector Search to initialize a collection called vector_store for us. Setting initialize-schema to true tells Spring AI to create the vector search index on our collection.
In the scale section, we tell Spring Boot to configure Java’s vaunted virtual threads. We’ll revisit this later.
In the health section, we tell Spring Boot’s Actuator to expose some details around the state of the application. We’ll revisit this later.
Initializing the vector store
Now, let’s get some code going. In the main class, called MongodbApplication.java in our example, we'll initialize the collection by reading some data from a .json file into the MongDB Atlas Vector Store. This .json file is available in the GitHub repo. We need to download it and add it to the resources folder in our application with the name dogs.json.
Now, we’ll open our MongodbApplication class, and add the necessary hints to read in our new resource.
@ImportRuntimeHints(MongoApplication.Hints.class)
@SpringBootApplication
public class MongodbApplication {
public static void main(String[] args) {
SpringApplication.run(MongoApplication.class, args);
}
static final Resource DOGS_JSON_FILE = new ClassPathResource("/dogs.json");
static class Hints implements RuntimeHintsRegistrar {
@Override
public void registerHints(RuntimeHints hints, ClassLoader classLoader) {
hints.resources().registerResource(DOGS_JSON_FILE);
}
}
// TBD
}
And now, we need to add this data to our vector store. Add the following code to the MongodbApplication class, and we’ll take a look at what it does:
@Bean
ApplicationRunner mongoDbInitialzier(MongoTemplate template,
VectorStore vectorStore,
@Value("${spring.ai.vectorstore.mongodb.collection-name}") String collectionName,
ObjectMapper objectMapper) {
return args -> {
if (template.collectionExists(collectionName) && template.estimatedCount(collectionName) > 0)
return;
var documentData = DOGS_JSON_FILE.getContentAsString(Charset.defaultCharset());
var jsonNode = objectMapper.readTree(documentData);
jsonNode.spliterator().forEachRemaining(jsonNode1 -> {
var id = jsonNode1.get("id").intValue();
var name = jsonNode1.get("name").textValue();
var description = jsonNode1.get("description").textValue();
var dogument = new Document("id: %s, name: %s, description: %s".formatted(
id, name, description
));
vectorStore.add(List.of(dogument));
});
};
}
This runner ingests data from the dogs.json file on the classpath and writes it to MongoDB Atlas using the Spring AI VectorStore interface. Each record is written as a simple string—id: %s, name: %s, description: %s. The format doesn’t matter as long as it’s consistent. This is what we’ll be using for generating our embedding, so make sure it includes all the data you want to reference.
The VectorStore handles both embedding generation and storage in one step. It uses an OpenAI-backed EmbeddingModel behind the scenes to convert each string into a vector, then stores that vector in MongoDB Atlas.
If the target collection doesn’t already exist, Spring AI will create it and automatically define a vector index on the embedding field. This means the collection and its index are ready for similarity search immediately after ingestion, with no manual setup required.
Building the assistant controller
Now, the easy part: building the assistant! We’ll define the AdoptionController. This is a simple Spring MVC controller that responds to requests and interacts with the AI model to recommend dogs based on user input.
@Controller
@ResponseBody
class AdoptionController {
private final ChatClient ai;
private final InMemoryChatMemoryRepository memoryRepository;
AdoptionController(ChatClient.Builder ai, VectorStore vectorStore) {
var system = """
You are an AI-powered assistant to help people adopt a dog from the adoption
agency named Pooch Palace with locations in Antwerp, Seoul, Tokyo, Singapore, Paris,
Mumbai, New Delhi, Barcelona, San Francisco, and London. Information about the dogs available
will be presented below. If there is no information, then return a polite response suggesting we
don't have any dogs available.
""";
this.memoryRepository = new InMemoryChatMemoryRepository();
this.ai = ai
.defaultSystem(system)
.defaultAdvisors(new QuestionAnswerAdvisor(vectorStore))
.build();
}
/// TBD
}
So far, all we’ve defined is a constructor into which we’ve injected the Spring AI ChatClient.Builder. The ChatClient is the center piece API for interacting with the auto-configured ChatModel representing our connection to OpenAI (or Ollama or whatever).
We want all interactions with the chat model to have some sensible defaults, including a system prompt. The system prompt gives the model a framing through which it should attempt to answer all subsequent questions. So, in this case, we’ve instructed it to answer all questions as though it were working at our fictitious adoption agency called Pooch Palace. As a result, it should politely decline or deflect any questions that don’t relate to our dog adoption agency.
In addition, we use a QuestionAnswerAdvisor backed by a MongoDB VectorStore. This ensures that the model attempts to answer questions based only on relevant documents—specifically, the vector-matched entries from our database of adoptable dogs.
We’ve also configured an advisor. Advisors are a Spring AI concept. Think of them as filters, or interceptors. They pre- and post-process requests made to the large language model. Here, the QuestionAnswerAdvisor lives in a separate dependency we need to explicitly add to our pom.xml:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
This advisor will search the MongoDB Atlas vector store on each request and do a similarity search, looking for data that might be germane to the user’s request. When somebody comes along inquiring about dogs of a particular characteristic, it will look for dogs that might match the characteristic. The results we get back will be a subselection of all the dogs available for adoption. We’ll transmit only that relevant subselection to the model. Remember, each interaction with a model has costs—both dollars and cents (or Euros!) and complexity costs. So the less data we send, the better. The model, then, takes our system prompt, the user’s question, and the included data from the vector store into consideration when formulating its response.
Models don't remember things. Think of them like Dory the goldfish from Finding Nemo. So we configure one more advisor which keeps a running transcript of the conversation between you and it and then reminds the model of what’s been said. This way, it'll remember you from one request to another.
Now, we’ll add an endpoint to our AdoptionController to communicate with our AI assistant, with a little bit of memory. This will allow our assistant to maintain a local chat log (10 messages back), to keep track of the conversation, and provide a bit more context to our LLM.
@GetMapping("/{user}/dogs/assistant")
String inquire(@PathVariable String user, @RequestParam String question) {
var memory = MessageWindowChatMemory.builder()
.chatMemoryRepository(memoryRepository)
.maxMessages(10)
.build();
var memoryAdvisor = MessageChatMemoryAdvisor.builder(memory).build();
return this.ai
.prompt()
.user(question)
.advisors(a -> a
.advisors(memoryAdvisor)
.param(ChatMemory.CONVERSATION_ID, user)
)
.call()
.content();
}
With all things taken together, you can now launch the program and then try it out:
http :8080/tkelly/dogs/assistant question==”do you have any neurotic dogs?”
With everything in place, it should return that there’s this dog named Prancer we might be interested in. (Boy, would we!)
Yes, we have a neurotic dog available for adoption. Meet Prancer, a demonic, neurotic dog who is not fond of humans, animals, or children, and resembles a gremlin. If you're interested in Prancer or would like more information, feel free to ask!
And there you have it. In no time at all, we went from zero to AI hero, making it easier to connect people with the dogs of their dreams… or nightmares!
Bring AI to production
Spring AI does more than just simple pet projects. It is designed for enterprise applications, and to fit in with your existing Spring applications. Transitioning to production involves ensuring security, scalability, and observability. Let’s break it down:
Security
It’s trivial to use Spring Security to lock down this web application. You could use the authenticated Principal#getName to use as the conversation ID too. What about the data stored in the collections? You can use MongoDB’s robust data encryption at rest.
Scalability
Each time you make an HTTP request to an LLM (or many databases), you’re blocking IO. This is a waste of a perfectly good thread. Threads aren't meant to just sit idle, waiting. Java 21 gives us virtual threads, which—for sufficiently IO-bound services—can dramatically improve scalability.
Enable them in application.properties with:
spring.threads.virtual.enabled=true
Instead of waiting for IO to complete, virtual threads free up resources, allowing your application to scale more effectively under load.
GraalVM native images
GraalVM compiles Java applications to native executables, reducing startup time and memory usage. Here’s how to compile your Spring AI app.
If you’ve got that set up as your SDK, you can turn this Spring AI application into an operating system and architecture specific native image with ease:
./mvnw -DskipTests -Pnative native:compile
This takes a minute or so on most machines but once it is done, you can run the binary with ease.
./target/mongodb
This program will start up in a fraction of the time that it did on the JVM. You might want to comment on the ApplicationRunner we created earlier since it's going to do IO on startup time, significantly delaying that startup. On my machine, it starts up in less than a tenth of a second.
Even better, you should observe that the application takes a very small fraction of the RAM it would've otherwise taken on the JVM.
Containerize for Docker
“That’s all very well and good,” you might say, “but I need to get this running on any cloud platform, and that means getting it into the shape of a Docker image.” Easy!
./mvnw -DskipTests -Pnative spring-boot:build-image
Stand back. This might take another minute still. When it finishes, you’ll see it’s printed out the name of the Docker image that’s been generated.
You can run it, remembering to override the hosts and ports of things it would've referenced on your host.
We’re on macOS, and amazingly, this application, when run on a macOS virtual machine emulating Linux, runs even faster (and right from the jump, too) then it would’ve on macOS directly. Amazing!
Observability
This application’s so darn good I’ll bet it’ll make headlines, just like our dog Prancer. And when that happens, you’d be well advised to keep an eye on your system resources and, importantly, the token count. All requests to an LLM have a cost—at least one of complexity, if not dollars and cents.
Spring Boot Actuator, powered by Micrometer, provides metrics out of the box.
Access the metrics endpoint to monitor token usage and other key indicators:
http://localhost:8080/actuator/metrics
Nice! You can use Micrometer to forward those metrics to your MongoDB time-series database to get a single pane of glass, a dashboard.
MongoDB Atlas: Fully managed and scalable
MongoDB Atlas is the managed cloud service for MongoDB, offering scalability and high availability across multiple cloud providers. With Atlas, MongoDB handles backups, monitoring, upgrades, and patches—letting you focus on building your application, not maintaining infrastructure. If managing databases isn’t core to your business, why not delegate it to the people who built MongoDB?
Conclusion
There you have it! You've just built a production-worthy, AI-ready, Spring AI- and MongoDB-powered application in no time at all. We’ve only begun to scratch the surface. Check out Spring AI 1.0 at the Spring Initializr today and learn more about MongoDB Atlas and the vector store support.
If you want to see more about what you can do with MongoDB, Spring, and AI, check out our tutorial on building a real-time AI fraud detection system with Spring Kafka and MongoDB. If you’re more interested in just getting started with Spring and MongoDB, we have a tutorial on that too!



Top comments (5)
Really loved how you broke down the RAG workflow and tied Spring AI with MongoDB so clearly - it actually feels doable now. Have you tried adapting this to more complex document types or other real-world use-cases beyond the demo?
Thank you! This is just the beginning. With Spring AI being GA now, we'll be exploring more advanced use cases that you can use and bring to production. Stay tuned!
pretty cool seeing spring and ai getting so close like this - honestly, every time stuff gets easier for regular devs it kinda changes the game for me. you think plugging all this ai into old school stacks will eventually be the norm?
Thanks
Thank you so much for the amazing content. I would be grateful if you have an idea on how we can do the same thing but with a SQL databases, or it would be so much hassle to migrate a full data warehouse that is based on SQL to document based DB like Mongo. Thanks again.