
Written by Andrew Baisden✏️
Creativity has reached new heights thanks to the rise of artificial intelligence (AI), which makes image generation possible with simple text prompts and descriptions capable of creating amazing works of art. Artists, designers, and developers alike have access to a wealth of AI tools to enhance traditional workflows.
In this article, we will build a custom AI image generator application that works offline. The web app will be built with React, and the core of the project will be powered by the Hugging Face Diffusers library, a toolkit for diffusion models. Hugging Face offers tools and models to develop and deploy machine learning solutions, focusing on natural language processing (NLP).
It also has a large open source community of pre-trained models, libraries, and datasets. We’ll pair these tools with Stable Diffusion XL, one of the most advanced and flexible text-to-image generation models currently available.
A significant part of this article will focus on the practical implementation that is achieved by running these kinds of models. Two main approaches will be compared: performing inference locally inside an application environment versus using a managed Hugging Face Inference Endpoint. With this comparison, we’ll see the trade-offs in performance, scalability, complexity, and cost.
The core technology: Hugging Face Diffusers and Stable Diffusion XL
Modern AI image creation is led by a class of models known as diffusion models. Picture an image going through a process that turns it into static noise, one pixel at a time. Diffusion models do the opposite by starting with noisy randomness, building structure, and then removing the noise until a visually recognizable image appears based on the text prompt.
This calculation can be intensive, but it allows anyone to create fantastically accurate and beautiful photos. Diffusion models can be complex and challenging to work with, but fortunately, the Hugging Face Diffusers library simplifies this process significantly.
Diffusers offers pre-trained pipelines that can be used to create images using just a few lines of code, along with precise control over the diffusion process for complex use cases.
It protects us from most of the complexity of the process, thus allowing us to spend more time creating our apps. In this project, we will use stabilityai/stable-diffusion-xl-base-1.0. Stable Diffusion XL (SDXL) is a huge leap for text-to-image generation, thanks to its capability of generating higher quality, more realistic, and more visually stunning pictures than models of the same class.
It also has a superior capacity for handling prompts and can generate more sophisticated outputs. You can check out the entire library of text-to-image models in the Text-to-Image page under the filters section.
Setting up our AI image generator app
Our image generator app will have a full-stack structure that uses local inference. This means that the app will run offline on our machine and won’t require internet access or calls to an external API. The frontend will be a React web app that runs in the browser, and it will make calls to our Flask backend server, which will be responsible for running the AI inference and logic locally using the Hugging Face Diffusers library.
AI inference is the process of using a trained AI model to make predictions or decisions based on new input data that it has not seen before. In its simplest form, this can mean training a model to learn a new pattern after analyzing some data. When the model can use what it has learned, this is referred to as “AI inference.”
For example, a model can be trained to tell whether it's looking at a picture of a cat or a dog. In more advanced use cases, it can be trained to perform text autocompletion, offer recommendations for a search engine, and even control self-driving cars.
This is what the design for our AI image generator app will look like: 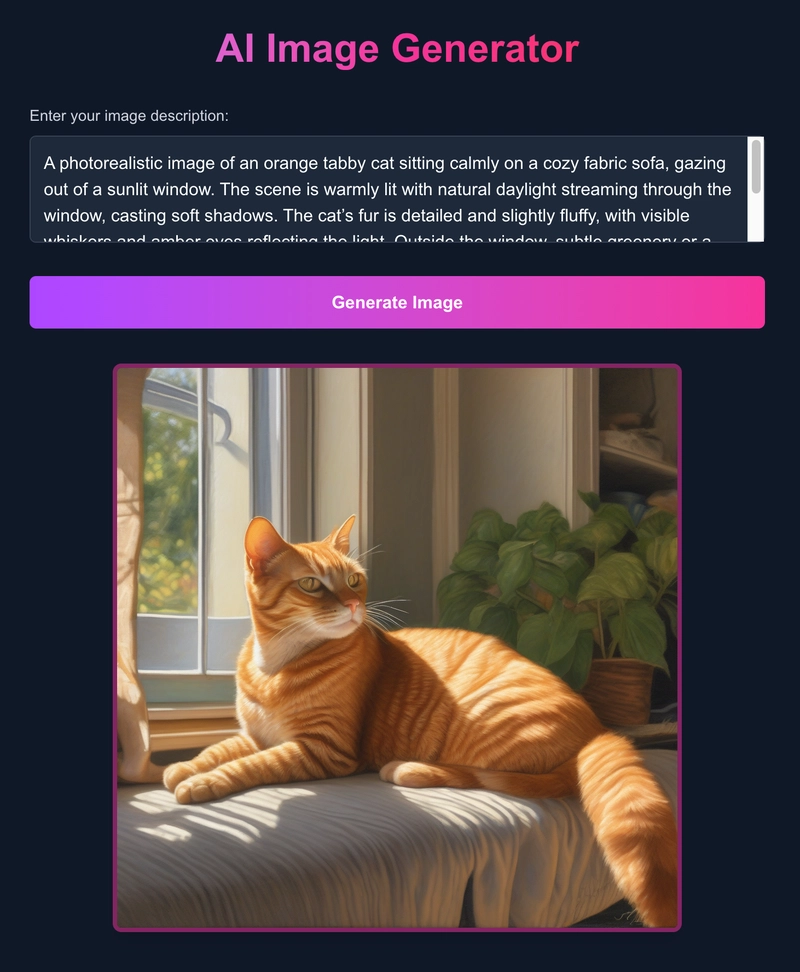
The technical stack
Our project will use the following technologies:
- React via Next.js on the frontend: Our app will use Next.js for the user interface. The frontend will have a text input box for entering the text and a button for generating the images. At the bottom will be a box to display the generated image, which will show a loading screen while the image generation is in progress
- Python/Flask on the backend: The backend server will be powered by the lightweight Python web framework, Flask. The Flask server will give us API endpoints, which are designed to receive the text prompt sent from the frontend to the backend. This is also when the Diffusers library will be used, as it will load and run the text-to-image model locally on our server while it performs the inference. The backend will then work with the generated image data and send it to our frontend
- Hugging Face Diffusers for AI model interaction: The workhorse of our backend is the Diffusers library. It provides the functionality and pre-trained pipelines to load and run text-to-image diffusion models, and it is specifically designed to support local inference for models such as Stable Diffusion XL on the same server that our Flask app runs on
Our application workflow
- User input: The user types their text prompt into the input field and then clicks on the Generate Image button
- Request to backend: The frontend then sends the user's text prompt to an API endpoint on our Python backend, which is designed to manage the HTTP request that was sent
- Backend inference (local): Our Python/Flask backend receives the prompt and then uses the Hugging Face Diffusers library, which loads our text-to-image model; in this case, Stable Diffusion XL. Our backend then uses the model's diffusion pipeline with the user's prompt to generate the image locally. If an NVIDIA GPU is present, then the image generation will be faster, as most AI models are optimized to run with the best performance with this type of configuration. For machines that don't have an NVIDIA GPU, like MacBooks, the process will default to using the CPU instead. As a result, the process will be slower unless it's one of the top-of-the-range MacBook Pro models
- Receiving and processing image data: As soon as the local inference has been completed, our backend gets the generated image data that the diffusers pipeline created. This image is then made ready for transmission back to our frontend as a Base64 string, ready for converting into an image
- Sending data to the frontend: An HTTP response is sent back to our frontend, which has the Base64 string
- Displaying the image: Our frontend receives the response and then extracts the image data, followed by updating the state for our
<img>tag to display the newly generated picture for the user
For better UX, the React frontend displays a loading indicator that remains as long as the backend is performing its inference, and error messages if anything goes wrong.
Running the application
You can clone or download the application from this GitHub repository. The README file contains instructions on how to set up the Flask backend and React frontend, which are straightforward and shouldn’t take very long. When you complete the setup, you need to run the backend and frontend servers in different tabs or windows on the command line with these commands:
# Run the Flask backend
python app.py
# Run the Next.js frontend
npm run dev
When you call the Diffusers library for the first time, it will automatically download the model files from the Hugging Face Hub. These models will then be stored in a local cache directory on your machine. On macOS/Linux, the default location for this cache is in your home directory under ~/.cache/huggingface/hub.
Inside that directory, you will find more subdirectories that are related to the models you have downloaded. For this model, the path might look something like this: ~/.cache/huggingface/hub/models--stabilityai--stable-diffusion-xl-base-1.0/.
The library will manage this cache automatically, so you don't need to interact with it directly. If you have downloaded other models using Hugging Face libraries, they will also be stored in this cache.
When you generate an image using the application below, you can see what it looks like in the terminal. For reference, an M1 MacBook Pro takes between two and 12 minutes to generate an image.
A high-spec computer will likely complete the process in seconds, especially if you have an NVIDIA GPU with CUDA: 
Local inference vs. Hugging Face inference endpoints
One of the most essential factors when deploying an AI model for inference is where the computation takes place. In our React app example, we had two choices:
- Executing the model locally on a machine (or self-hosted server)
- Taking advantage of a managed service like Hugging Face Inference Endpoints
Let’s see how both models compare!
Local inference
When a diffusion model is run locally, the computations are performed on the user's machine or a server, which is directly under your control, and not a third party like a shared hosting provider. The pros to this approach include:
- Full control: You completely control the environment, the dependencies, and the version and types of the models that you use
- Data privacy: All images are generated and processed in your local environment, which means that you have data privacy and security. This is good when working with sensitive applications or generating data that needs to be compliant and safe
- Potentially less expensive (with current hardware): When you already own high-performance hardware like a high-powered GPU, the cost per generation can be very close to zero. This means that you don't ever have to pay for an online text-to-image service if you have a system set up that generates high-quality images locally
- Offline capability: After it has been set up, inference can be performed without a persistent internet connection, unless you are downloading new models
The cons to this process include:
- Hardware requirements: Diffusion models, like SDXL, are very compute-intensive and require a top-of-the-line dedicated graphics card (GPU) with lots of VRAM. This is a large barrier for the average user because it adds cost and complexity when setting up your environment
- Complex setup and maintenance: You also have to consider that you will have to install all of the dependencies, manage the model weights, and set up the environment. All of this manual, hands-on work takes time and requires technical expertise
- Scalability issues: Scaling local inference to handle multiple users or a high volume of requests at the same time is difficult and expensive because it requires more hardware and load balancing
- Performance variability: Performance is dependent on the user's or server's machine hardware, so generation times vary. A high-performance machine could potentially generate images in seconds or minutes, whereas a low-performance machine could take hours or more, depending on the type of generation taking place
- Energy consumption: A lot of electricity is required to power high-performance GPUs for inference
Hugging Face Inference Endpoints
Unlike local inference, Hugging Face Inference Endpoints are managed online on Hugging Face infrastructure. Models can be accessed through an easy-to-use API call. The pros to using this approach include:
- No hardware management: There's no need to purchase, set up, or maintain expensive GPU hardware locally because everything is already done and ready to use. You can also choose the hardware or GPU, sometimes getting access to setups that would be highly costly if purchased for your own local setup
- Easy deployment: Simple deployment of a model using the Hugging Face UI or API
- Scalability: Inference Endpoints automatically scale based on demand, handling different levels of traffic without the need for manual intervention
- Less maintenance: The Hugging Face platform can handle the infrastructure, security, and environment setup, so you don't have to worry about these technicalities
- Pay-as-you-go: You usually only need to pay for the compute time that you use, and this can be cost-effective when used sporadically
- Improved performance: The endpoints are most likely running on highly optimized hardware setups, which cloud companies have provided. This can result in potentially faster inference time than standard consumer hardware
The cons to this approach include:
- Expensive (for large volume): For regular or very large volume usage, the overall cost of pay-as-you-go is more than the cost of owning and maintaining your own hardware in the long term
- Dependence on external service: Your app is dependent on the availability and responsiveness of the Hugging Face infrastructure. If the service goes down, your app goes down
- Cold starts and latency: The first request after idle may have a "cold start" latency while the endpoint is warming up, although further requests are usually faster
- Data transfer: Your application and the Hugging Face servers exchange all of your input prompts and output images, which means that you have less privacy because you are using an external platform
Comparison: Setup, cost, and performance
When it comes to setup, local inference is highly technical in terms of setting up the hardware and software stack. Hugging Face Endpoints have a much less technically complicated setup and a focus on model selection and setup through their platform.
As for cost, local inference is pricey to set up in terms of hardware and upfront costs, but it potentially has lower ongoing costs if usage is extremely high and the hardware is performant. Inference Endpoints are cheap upfront but have costs that accumulate depending on use, which can be more stable and manageable for variable usage.
Performance is greatly dependent on hardware, with inference endpoints having less variable performance (following cold starts) on optimized hardware, the trade-off being that latency arises from network communication.
Choosing the right approach
Choosing between Hugging Face Inference Endpoints and local inference mostly depends on the type of requirements and constraints of your project: Use local inference if you:
- Have access to powerful GPU hardware
- Prefer complete control and data privacy
- Anticipate extensive and constant use where the unit cost per inference is a factor
- Have the technical expertise for implementation and maintenance
Choose Hugging Face Inference Endpoints if you:
- Don't want to handle hardware management overhead and cost
- Need easy scalability
- Like a pay-as-you-go pricing model
- Want to get started quickly
- Are willing to trust a managed service
Handling image data and communication
When an image is generated on the backend, it needs to be optimally transmitted to the frontend React app. The biggest concern is transferring binary image data over HTTP. Two techniques can be used to solve this:
- Base64 encoding: This is where the encoding is done for the image, and the data is converted into a string form directly in the API response
- Temporary URLs: The image is temporarily stored on the backend, and then a URL is provided for the frontend app to fetch
One of the best aspects of using the Base64 encoding method is that it integrates the image directly into the API's JSON response as it converts the binary data into a string of text. This can simplify the transfer because the image data is bundled along with other response data, so it can be embedded directly into an image tag as a data URL.
However, a big drawback to this approach is the 33% increase in data size due to the encoding process. Very small or multiple images can significantly increase the payload, making network transfer time slower and even impacting frontend speed as it is forced to process much more data. On the other hand, the temporary URL method has the backend to save the generated image file and return a short-lived URL pointing to its location.
The frontend can then use this URL to retrieve the image independently. This approach keeps the initial API response payload small and uses the browser's enhanced image loading efficiency. Even though it adds backend overhead for handling storage and generating URLS, it more or less offers enhanced performance and scalability with larger images or for generating more images, as the main data channel is not filled with large image content.
Choosing between these methods mainly comes down to anticipating image sizes and balancing backend complexity with frontend responsiveness.
Challenges and considerations
One of the largest issues with building an AI image generation app, especially when performing inference on a local machine or a self-hosted server, is handling the high computational demands.
For example, Stable Diffusion XL and similar models need fast, high-capacity GPUs, which can be very costly. They might also require special setup and technical knowledge, which the average non-technical person might not have.
Regardless, with any inference method, good error handling is crucial. This means using user prompt validation to limit inappropriate or unsafe requests and handling potential failures.
In addition to the basic implementation, performance improvement of the application is a significant requirement when attempting to provide an uninterrupted experience because image generation can be time-consuming.
Strategies such as using load screens, queueing requests in the backend, exploring model optimization, or caching techniques can help with any latency problems.
Security should also be taken into account, such as storing sensitive API keys securely when using managed endpoints, sanitizing user input to avoid vulnerabilities, and potentially using content moderation on produced content, which are important measures for creating a secure and responsible application.
Conclusion
The world of generative AI is evolving fast, and the best way to understand what it can and can't do is by building projects to test the wide variety of tools available. Use this guide as a reference point for building a React-based AI image generation app. The project we built is good enough to be a basic minimum viable product (MVP).
You can experiment with more features using the other text-to-image models on the Hugging Face Hub. There’s no limit to what you can create with all the tools we have at our disposal today!
Get set up with LogRocket's modern error tracking in minutes:
- Visit https://logrocket.com/signup/ to get an app ID.
- Install LogRocket via NPM or script tag.
LogRocket.init()must be called client-side, not server-side.
NPM:
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
Script Tag:
Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>
3.(Optional) Install plugins for deeper integrations with your stack:
- Redux middleware
- ngrx middleware
- Vuex plugin



Top comments (0)