Introduction
In this post, we're going to take a deeper dive into Apache Kafka. If you'd like an introduction to Event-Driven Architectures, feel free to check out my previous article.
Kafka is a powerful stream processing tool. It's like a super efficient digital post office for real time data. Instead of sending single letters, it handles streams of messages (like a continuous flow of packages) between different applications or systems. It's designed to be incredibly fast, reliable, and can manage huge amounts of data, making it perfect for things like tracking user activity on a website, processing financial transactions, or collecting data from sensors.
| Concept | Description |
|---|---|
| Producer | Sends data or publishes messages to Kafka. |
| Consumer | Reads or subscribes to data from Kafka to process it. Multiple consumers can subscribe to the same data. |
| Topic | a specific channel or a category where different kinds of data are organized(like a queue). It's like having different mailboxes in a post office, each labeled for a particular type of mail. Producers send their messages to a specific topic, and consumers who are interested in that type of data will subscribe to that particular topic to receive the messages. |
| Partition | A physical division of a Topic. Messages within a Topic are split into Partitions for scalability and parallel processing. This division allows Kafka to handle more data and process it faster because different parts of the data can be processed at the same time. |
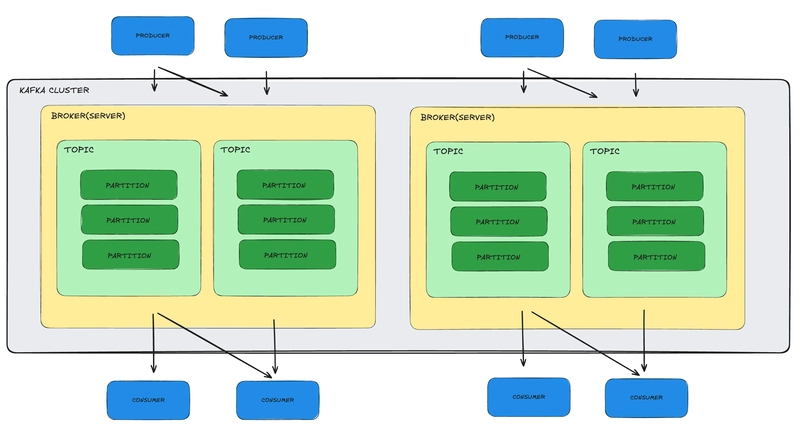
| Broker | A Kafka server responsible for storing topic partitions and handling read and write requests from producers and consumers. |
| Cluster | A group of Kafka brokers working together to provide fault tolerance and high availability. |
| Zookeeper | A centralized service used for coordinating the Kafka cluster (configuration, synchronization, and group services; optional in newer versions). Kafka newer versions (2.8+) started moving away from Zookeeper, they introduced KRaft Mode, meaning Kafka can now manage itself without needing Zookeeper. |
Example of topic and partition to understand it better.
A topic is like a book (it’s about a single subject — "Orders").
Partitions are chapters of the same book, breaking the content into smaller pieces so people can read/write different parts at the same time.
Multiple topics would be different books ("Orders", "Payments", "Shipments").
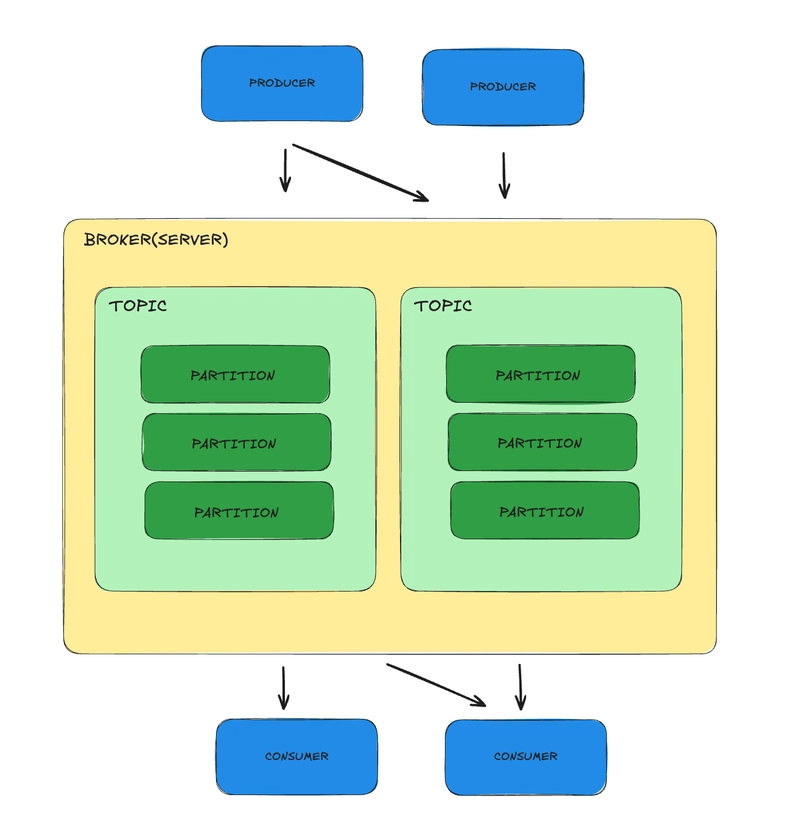
Why Partitions Matter?
- Scalability: More partitions = more parallelism = faster reading/writing.
- Ordering: Kafka guarantees message order within a single partition. If you use a key (like a user ID), all events with the same key are sent to the same partition, ensuring they are processed in order. While multiple user IDs can share the same partition, Kafka still maintains the correct order for each individual key. However, Kafka does not guarantee ordering across different partitions.
- Persistance: Messages are kept for a configured time, even after being read. What happens when the events have been consumed in Kafka? Are they removed from the topic? No, Kafka’s Model: Log-Based, Not Queue-Based. Events remain in the topic for a fixed period,even after being consumed. That means:
- Events are written to a topic (which is like a log file).
- Consumers read from the log and track their own offset. The offset is a pointer to the last message they successfully read.
- Events stay in the topic for a fixed duration (based on the retention time), even after they’ve been consumed.
- Fault tolerance: Kafka replicates each partition, copies are made and stored on other brokers (servers). How? Each partition has a leader broker that handles writes/reads. Another broker acts as a follower (replica) to back up the partition.
Kafka Consumer Groups
A consumer group is a set of consumers that collaboratively consume messages from Kafka topics. Typically, these are multiple instances of the same application running in parallel, like three instances of a microservice deployed for load balancing. Inside a consumer group, each partition is assigned to only one consumer, so every message from a partition is processed by just one instance. This helps spread the workload evenly across the consumers.
How Does It Work?
Let’s say you have:
- A Kafka topic with 3 partitions (P0, P1, P2).
- A consumer group with 2 consumers/instances(EC2): C1 and C2.
Kafka will assign partitions to consumers in the group:
- C1 might read from P0 and P1.
- C2 reads from P2.
Each partition is read by only one consumer in the group at a time.
But the same topic can be consumed by multiple different consumer groups independently.
Why This Matters / What’s the Goal?
The goal is to:
- Distribute the load between multiple service instances.
- Scale horizontally — more partitions = more consumers = more throughput.
- Make your system fault-tolerant, if one EC2 instance fails, Kafka can reassign its partition to the other instance.
Possible Scenario: One Instance Fails
Let’s say:
- Your Kafka topic has 2 partitions.
- You have 2 EC2 instances running your microservice (both are consumers in the same group).
- Instance 1 (Consumer A) → handles Partition 0
- Instance 2 (Consumer B) → handles Partition 1
Suddenly, Instance 1 crashes.
What Kafka Does Automatically
1.Detects the Failure
- Kafka uses heartbeats to check if consumers are alive.
- If a consumer stops sending heartbeats (default timeout is ~10 seconds), Kafka marks it as dead.
2.Triggers a Rebalance
- Kafka reassigns the partitions that the dead consumer was handling.
- Now, Instance 2 (Consumer B) gets both Partition 0 and Partition 1.
3.Continues from Last Offset
- Kafka tracks the offsets for each partition in the consumer group.
- Consumer B resumes from the last committed offset of Partition 0.
- No messages are lost or reprocessed unless your app is configured to do so.
What Happens When Instance 1 Comes Back?
- It rejoins the consumer group.
- Kafka rebalances again.
- The workload (partitions) may be redistributed:
- Instance 1 may take back one of the partitions.
Kafka Retention Time cleanup.policy=delete
Means how long Kafka keeps a message in a topic, regardless of whether it's been read or not. The purpose is to allow consumers to re-read messages for a certain period of time (for recovery, auditing, or analytics).
How does it work?
Set via topic configuration:
retention.ms (in milliseconds): retention.ms = 604800000 → 7 days
Kafka will delete old messages (per partition) after they reach this age and the disk space is available for new data.
Note: You can also configure by size, using retention.bytes, but time based is more common.
Kafka Log Compaction cleanup.policy=compact
Compaction is a process that ensures only the latest value for each key is retained in a topic. Useful for state stores, configurations, or changelogs.
How does it work?
Compaction is enabled by setting cleanup.policy=compact (the default is delete). You can also combine both policies by setting cleanup.policy=compact,delete. In this case, Kafka will compact messages to keep only the latest value per key, while also deleting older segments based on the configured retention time or size.
Kafka will keep the most recent message per key and remove older ones. Take into account that compaction is asynchronous, it runs in the background and is not instant. Kafka compaction is perfect when each message represents an update to a specific key, and you only care about the most recent value.
Imagine you write:
key1 → value1
key2 → value2
key1 → value3
key2 → value2
key1 → value3 (latest value for key1)
Serialization and Deserialization in Kafka
Serialization: converting data (an object, a record, or a message) into a byte stream. Kafka requires all messages to be in a byte format, so producers must serialize data before sending it to Kafka.
Deserialization: reverse process, converting the byte stream back into the original data format.
Kafka is format agnostic, it doesn’t care what format your data is in, as long as it’s a byte array.
- The producer serializes the message into bytes.
- Kafka stores it.
- The consumer deserializes the message into a usable format (JSON, Avro, etc).
Avro + Schema Registry Is the Preferred Choice
Avro + Schema Registry is currently the most widely adopted serialization strategy in large scale systems with many microservices.
Key Points
- Compactness:Avro serializes data in a compact binary format, which significantly reduces message size compared to JSON
- Schema validation: Avro enforces a schema, which means producers and consumers both agree on the structure of the data. The schema itself isn't embedded in each message, only a small schema ID is sent — reducing payload size and allowing strong data contracts between services
- Schema evolution: Avro is designed to support changes over time, add optional fields, remove unused fields, change default values. This is crucial in microservices, where one team might update a service without breaking another.
At small scale, JSON is easier. But at enterprise or production scale, Avro makes data governance, backward compatibility, and performance manageable.
Example
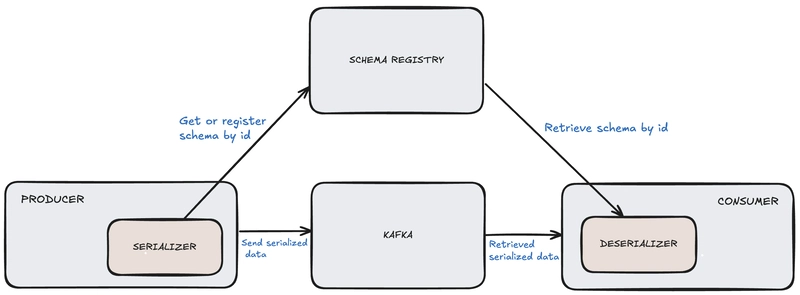
Producer Side (Serialization)
- When a producer sends a message, it:
- Serializes the object using the Avro schema.
- Registers the schema (if new) in the Schema Registry.
- Includes the schema ID in the message payload (usually as a small header or prefix).
Consumer Side (Deserialization)
- When the consumer receives a message, it:
- Reads the schema ID from the message.
- Fetches the schema from the Schema Registry using that ID.
- Deserializes the message using the schema (to a GenericRecord or specific java class).
Let's see some code
- Avro serialization/deserialization using Confluent Schema Registry.
- Producer and consumer of a
Userobject. - Automatic generation of Java classes from .avsc.
Avro Schema: src/main/avro/User.avsc
{
"type": "record",
"name": "User",
"namespace": "com.example.kafka.avro",
"fields": [
{ "name": "id", "type": "string" },
{ "name": "name", "type": "string" },
{ "name": "email", "type": ["null", "string"], "default": null }
]
}
Kafka Configuration: application.yml
spring:
kafka:
bootstrap-servers: localhost:9092 # where the Kafka broker(s) are running.
properties:
schema.registry.url: http://localhost:8081 # where the Confluent Schema Registry is running
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: io.confluent.kafka.serializers.KafkaAvroSerializer # Converts the value (like an Avro User object) into binary Avro format, with metadata that links to its schema stored in Schema Registry
consumer:
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: io.confluent.kafka.serializers.KafkaAvroDeserializer # Converts the binary Avro back into a usable Java object, using the schema from Schema Registry.
properties:
specific.avro.reader: true # Kafka uses the generated Avro class, which gives you compile-time type safety. If false, you'd get a GenericRecord
listener:
missing-topics-fatal: false # it will not fail if the topic doesn’t exist yet — useful during development or if topics are created dynamically
KafkaProducer.java
import com.example.kafka.avro.User;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
@Component
public class KafkaProducer {
private final KafkaTemplate<String, User> kafkaTemplate;
public KafkaProducer(KafkaTemplate<String, User> kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
public void sendUser(User user) {
kafkaTemplate.send("user-topic", user.getId().toString(), user);
System.out.println("Produced User: " + user);
}
}
KafkaConsumer.java
import com.example.kafka.avro.User;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
@Component
public class KafkaConsumer {
@KafkaListener(topics = "user-topic", groupId = "user-group")
public void consume(User user) {
System.out.println("Consumed User: " + user);
}
}
KafkaAvroApplication.java
@SpringBootApplication
public class KafkaAvroApplication implements CommandLineRunner {
@Autowired
private KafkaProducer producer;
public static void main(String[] args) {
SpringApplication.run(KafkaAvroApplication.class, args);
}
@Override
public void run(String... args) {
User user = User.builder()
.setId("u1")
.setName("Jhoni")
.setEmail("jhoni@example.com")
.build();
producer.sendUser(user);
}
}

Top comments (0)