Introduction
When you work with data streaming in the real world, sooner or later you'll be hit by duplicate events. They're a classic headache, especially in modern data stacks where various sources might be trying to tell you about the same underlying action. Imagine your CRM syncing customer data with your email marketing tool, while your web analytics platform and Meta Ads both track the same conversions. Suddenly you're seeing the same customer action reported through four different pipelines, with slight variations in timing and format. Network glitches, producers retrying sends, or even simple synchronization delays between platforms can compound the problem - now you're counting the same sale four times or sending a customer identical notifications through multiple channels. Not ideal, right?
We're going to build a basic but functional pipeline to tackle this exact scenario. We'll read data from Kafka, use GlassFlow to filter out duplicates within a recent time window (regardless of which source system they came from), and store the clean, unique events in ClickHouse. Think of this as your "Streaming Deduplication 101" for handling real-world multi-source data integration. We'll keep it practical and use tools you'll likely encounter, focusing on identifying the same logical events even when they arrive through different pipelines. But before we start, let's go through some basic information.
What Is Deduplication in Data Streaming?
Deduplication in data streaming is the process of identifying and removing duplicate records from a continuous stream of data.Unlike batch processing where you have complete datasets to work with, streaming deduplication requires making decisions about individual events in real-time, often without complete knowledge of all data that has been processed.
In streaming systems, it’s not about removing every duplicate that ever existed—just the ones within a reasonable recent time frame. This is usually based on an identifier like event_id, combined with a time-based window.
In simple terms, if two events arrive with the same ID within the deduplication window (e.g., one hour), we only keep the first one and drop the rest.
Why Is Deduplication Needed in Streaming?
In modern data architectures, events often flow into your pipelines from multiple integrated systems—your CRM syncing with email platforms, ad networks reporting conversions, and analytics tools tracking user behavior. While this redundancy improves fault tolerance, it creates a thorny problem: the same logical event (like a purchase or signup) may arrive through different channels, at different times, and in slightly different formats.
These duplicates can skew analytics, cause double-counting, or annoy users with repeated notifications. Deduplication helps maintain data accuracy and trust in real-time pipelines.
What We Are Building
We are going to solve a simple problem in this article that is a stream of events in Kafka might contain duplicates and our goal is to process this stream, identify and discard duplicates based on unique event_id within a certain window and save only the unique events.
The Tools:
- Kafka: Our trusty message bus. Events land here first.
- GlassFlow: Our processing engine. GlassFlow will read data from Kafka, check for duplicates, and write to ClickHouse.
- ClickHouse: A fast columnar database. It will be our final destination for clean data. And, for simplicity in this tutorial, we'll cleverly use it as our "memory" or state store to remember which events we've already seen recently.
Defining the Deduplication Window
We'll implement a sliding window deduplication strategy where we only consider events duplicates if they occur within a specific time frame (e.g., the last 1 hour). This balances memory usage with practical deduplication needs. Events older than the window are considered "expired" and won't be checked against new events.
Setting Up the Infrastructure
Let’s go over the infrastructure that we need to setup. We have three main components, Kafka, GlassFlow and ClickHouse.

Now, GlassFlow itself consists of Nats, the UI, the App, and Nginx.
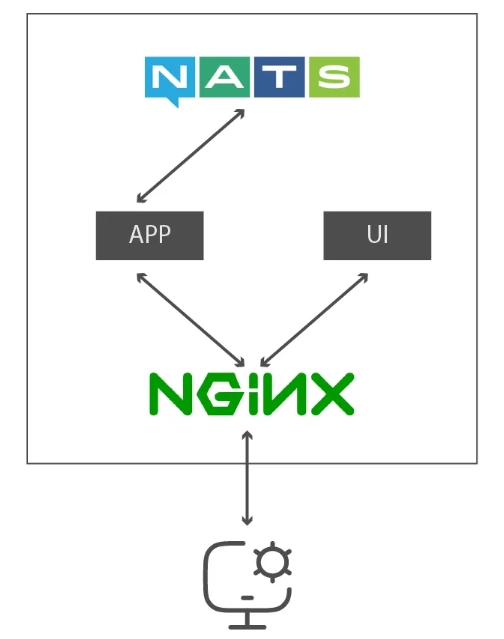
Now that you know the infrastructure that we need, let’s set them up using Docker. Note, we have a lot of infrastructure, so our docker-compose.yaml is a bit large.
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.9.0
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
KAFKA_OPTS: "-Djava.security.auth.login.config=/etc/zookeeper/jaas/zookeeper_jaas.conf"
ZOOKEEPER_AUTH_PROVIDER_1: org.apache.zookeeper.server.auth.SASLAuthenticationProvider
ZOOKEEPER_REQUIRECLIENTAUTHSCHEME: sasl
volumes:
- ./config/kafka/zookeeper/jaas.conf:/etc/zookeeper/jaas/zookeeper_jaas.conf
kafka:
image: confluentinc/cp-kafka:7.9.0
container_name: kafka
ports:
- "9092:9092"
- "9093:9093"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:SASL_PLAINTEXT,EXTERNAL:SASL_PLAINTEXT,DOCKER:SASL_PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka:9092,EXTERNAL://localhost:9093,DOCKER://kafka:9094
KAFKA_LISTENERS: INTERNAL://0.0.0.0:9092,EXTERNAL://0.0.0.0:9093,DOCKER://0.0.0.0:9094
KAFKA_SASL_ENABLED_MECHANISMS: PLAIN
KAFKA_SASL_MECHANISM_INTER_BROKER_PROTOCOL: PLAIN
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_AUTO_CREATE_TOPICS_ENABLE: "true"
KAFKA_OPTS: "-Djava.security.auth.login.config=/etc/kafka/jaas/kafka_server.conf"
volumes:
- ./config/kafka/broker/kafka_server_jaas.conf:/etc/kafka/jaas/kafka_server.conf
- ./config/kafka/client/client.properties:/etc/kafka/client.properties
depends_on:
- zookeeper
clickhouse:
image: clickhouse/clickhouse-server
user: "101:101"
container_name: clickhouse
hostname: clickhouse
ports:
- "8123:8123"
- "9000:9000"
volumes:
- ./config/clickhouse/config.d/config.xml:/etc/clickhouse-server/config.d/config.xml
- ./config/clickhouse/users.d/users.xml:/etc/clickhouse-server/users.d/users.xml
nats:
image: nats:alpine
ports:
- 4222:4222
command: --js
restart: unless-stopped
ui:
image: glassflow/clickhouse-etl-fe:stable
pull_policy: always
app:
image: glassflow/clickhouse-etl-be:stable
pull_policy: always
depends_on:
- nats
restart: unless-stopped
environment:
GLASSFLOW_LOG_FILE_PATH: /tmp/logs/glassflow
GLASSFLOW_NATS_SERVER: nats:4222
volumes:
- logs:/tmp/logs/glassflow
nginx:
image: nginx:1.27-alpine
ports:
- 8080:8080
depends_on:
- ui
- app
volumes:
- logs:/logs:ro
- ./config/nginx:/etc/nginx/templates
restart: unless-stopped
environment:
NGINX_ENTRYPOINT_LOCAL_RESOLVERS: true
volumes:
logs:
We just orchestrates seven containers. Some of the container also requires setting files, that I will show below. Most of the config files are related to security and credentials, this is needed because the GlassFlow app requires a proper use of username and password.
Zookeeper
We will fill the content of the jaas.conf as follow.
Server {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="admin"
password="admin-secret"
user_admin="admin-secret"
user_client-user="supersecurepassword";
};
Kafka
For Kafka we will have two configuration files:
kafka_server_jaas.conf
KafkaServer {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="admin"
password="admin-secret"
user_admin="admin-secret"
user_client-user="supersecurepassword";
};
KafkaClient {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="admin"
password="admin-secret";
};
Client {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="admin"
password="admin-secret";
};
client.properties
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \
username="admin" \
password="admin-secret";
ClickHouse
For ClickHouse we need to define two config files:
config.d/config.xml
<clickhouse replace="true">
<logger>
<level>debug</level>
<log>/var/log/clickhouse-server/clickhouse-server.log</log>
<errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog>
<size>1000M</size>
<count>3</count>
</logger>
<display_name>gfc</display_name>
<listen_host>0.0.0.0</listen_host>
<http_port>8123</http_port>
<tcp_port>9000</tcp_port>
<user_directories>
<users_xml>
<path>users.xml</path>
</users_xml>
<local_directory>
<path>/var/lib/clickhouse/access/</path>
</local_directory>
</user_directories>
</clickhouse>
users.d/users.xml
<?xml version="1.0"?>
<clickhouse replace="true">
<profiles>
<default>
<max_memory_usage>10000000000</max_memory_usage>
<use_uncompressed_cache>0</use_uncompressed_cache>
<load_balancing>in_order</load_balancing>
<log_queries>1</log_queries>
</default>
</profiles>
<users>
<default>
<password>secret</password>
<access_management>1</access_management>
<profile>default</profile>
<networks>
<ip>::/0</ip>
</networks>
<quota>default</quota>
<access_management>1</access_management>
<named_collection_control>1</named_collection_control>
<show_named_collections>1</show_named_collections>
<show_named_collections_secrets>1</show_named_collections_secrets>
</default>
</users>
<quotas>
<default>
<interval>
<duration>3600</duration>
<queries>0</queries>
<errors>0</errors>
<result_rows>0</result_rows>
<read_rows>0</read_rows>
<execution_time>0</execution_time>
</interval>
</default>
</quotas>
</clickhouse>
Nginx
For Nginx, we define the default.conf.template as follows.
server {
listen 8080;
server_name default_server;
location /logs {
autoindex on;
alias /logs;
}
location /api/v1 {
resolver ${NGINX_LOCAL_RESOLVERS} valid=1s;
set $backend "http://app:8080";
proxy_pass $backend;
}
location / {
resolver ${NGINX_LOCAL_RESOLVERS} valid=1s;
set $frontend "http://ui:3000";
proxy_pass $frontend;
}
}
In this config, we set the proxy pass to the app server and the ui server. This configuration allows us to access the GlassFlow UI via a browser from http://localhost:8080
To start the system, open your terminal in the same directory, and run:
$ docker-compose up -d
his command downloads the necessary images (if you don't have them) and starts the containers in the background. Give it a minute or two. You can check if they're running with docker ps.
Setting Up Kafka Topic
We need a place for our raw, potentially duplicated events to land. Let's create a Kafka topic called users.
$ docker-compose exec kafka kafka-topics \
--create \
--topic users \
--bootstrap-server localhost:9093 \
--partitions 1 \
--replication-factor 1 \
--command-config /etc/kafka/client.properties
Preparing ClickHouse Table
Now, let's create the tables in ClickHouse. Connect to the ClickHouse client via Docker:
$ docker-compose exec clickhouse clickhouse-client
Inside the ClickHouse client prompt, run the following SQL command:
CREATE TABLE IF NOT EXISTS users_dedup (
event_id UUID,
user_id UUID,
name String,
email String,
created_at DateTime
) ENGINE = MergeTree
ORDER BY event_id
Why MergeTree? It's ClickHouse's go-to engine for performance. ORDER BY helps ClickHouse store and query data efficiently.
Type exit to leave the ClickHouse client.
Making Some (Duplicate) Data! The Producer
Here is our producer Python file.
import json
import time
import uuid
from datetime import datetime
from kafka import KafkaProducer
from faker import Faker
fake = Faker()
# Configuration
KAFKA_BROKER = "localhost:9093"
TOPIC = "users"
# Create producer
producer = KafkaProducer(
bootstrap_servers=[KAFKA_BROKER],
value_serializer=lambda v: json.dumps(v).encode("utf-8"),
security_protocol="SASL_PLAINTEXT",
sasl_mechanism="PLAIN",
sasl_plain_username="admin",
sasl_plain_password="admin-secret",
)
# Keep track of some recent event IDs to duplicate
recent_events = []
def generate_event():
event_id = str(uuid.uuid4())
timestamp = datetime.now().isoformat()
return {
"event_id": event_id,
"user_id": str(uuid.uuid4()),
"created_at": timestamp,
"user_name": fake.user_name(),
"user_email": fake.email(),
}
if __name__ == "__main__":
try:
while True:
# Generate new event
event = generate_event()
print(f"Producing event: {event['event_id']}")
producer.send(TOPIC, value=event)
# Occasionally duplicate a recent event
if recent_events and time.time() % 5 < 1: # ~20% chance
duplicate_event = {**event, "event_id": recent_events[-1]}
print(f"Producing DUPLICATE: {duplicate_event['event_id']}")
producer.send(TOPIC, value=duplicate_event)
# Track recent events (keep last 5)
recent_events.append(event["event_id"])
if len(recent_events) > 5:
recent_events.pop(0)
time.sleep(1) # Slow down the producer
except KeyboardInterrupt:
producer.close()
Note: It is a good idea to run the producer.py to verify that it is working. Furthermore, it helps the GlassFlow ETL app to understand the schema. Otherwise, you have to manually define the schema.
Setting Up GlassFlow Pipeline
There are two ways to create a pipeline. We can do it using the GlassFlow UI or using a Python scripts. In this tutorial, I will be using the GlassFlow UI. You can access the GlassFlow UI via a browser by entering http://localhost:8080.
Step 1. Setup Kafka Connection
We are going to fill this with the following connection details. They match the configuration that we have define above.
Authentication Method: SASL/PLAIN
Security Protocol: SASL_PLAINTEXT
Bootstrap Servers: kafka:9094
Username: admin
Password: admin-secret

Step 2. Selecting the Kafka Topic
At this step we will set the Kafka topic that we have defined in the previous section. If you have published some event to Kafka, the sample event will be shown automatically. Otherwise, you have to define them yourself.

Step 3. Define Duplicate Keys
At this step, we need to choose event_id as the deduplication key.
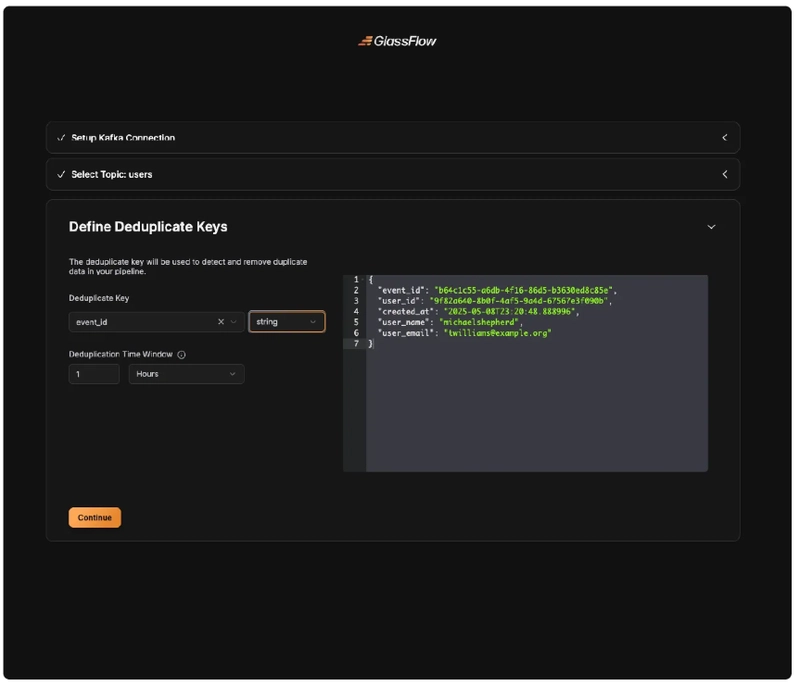
Step 4. Setup the ClickHouse Connection
We are going to use the following connection to connect to ClickHouse.
Host: clickhouse
HTTP/S Port: 8123
Native Port: 9000
Username: default
Password: secret
Use SSL: false

Step 5. Select Database and Table
In this step, we will define the database and the table. Note that you will need to map the incoming data fields to the database fields in this step.
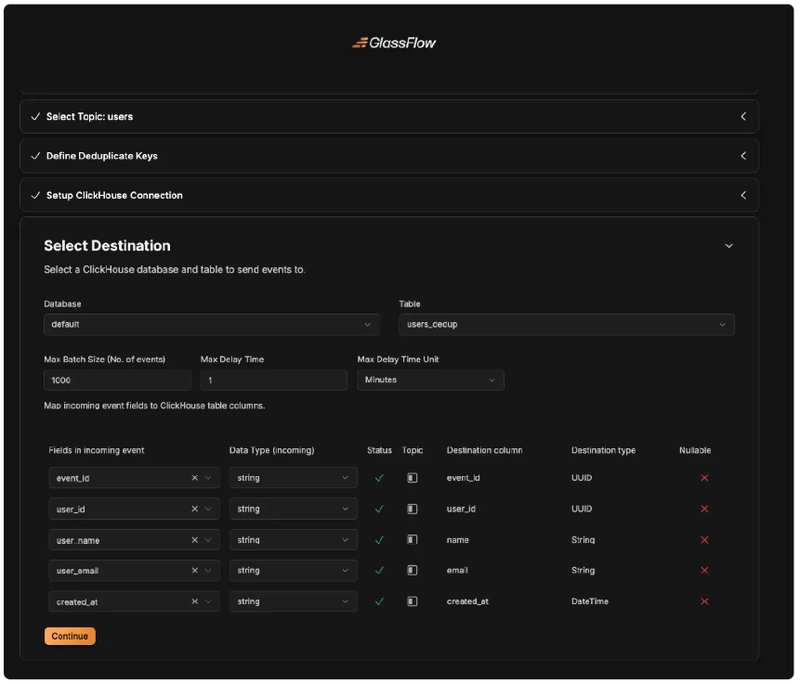
Step 6. Confirmation Page
GlassFlow will present us with a summary of the configuration and we can then deploy the pipeline.
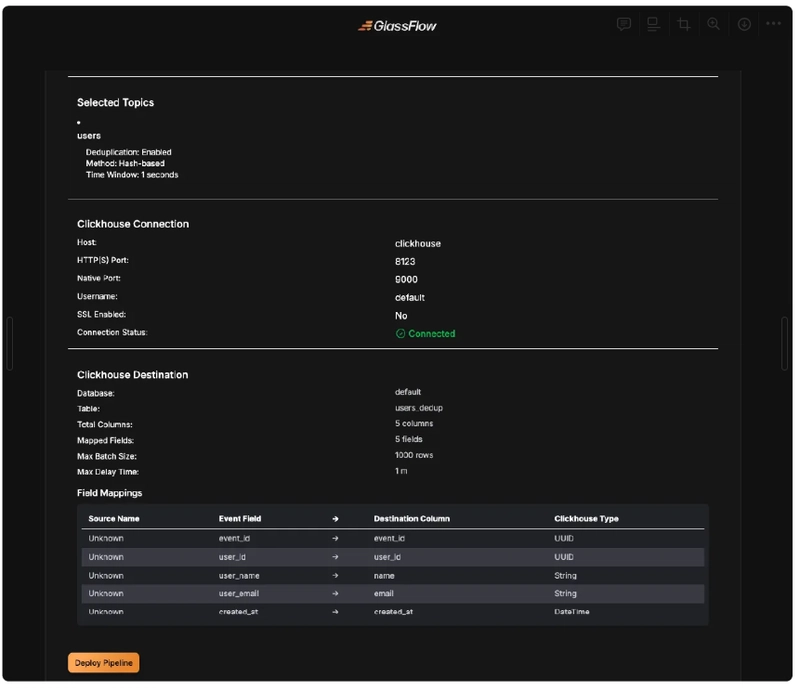
If everything is setup correctly we will see the following notification.

Running and Verifying
Now let’s run our and verify the result. If you haven’t started the infrastructure, you can start like the following.
$ docker-compose up -d
Now we can run the producer.py.
$ python producer.py
Observe the console - you should see both new events being processed and duplicates being detected. You should see something like the following.
$ python producer.py
Producing event: 040e27af-691e-4500-bc17-19d4b5630fa3
Producing event: 1fdbf388-8313-48ea-9308-54eca5a100f1
Producing event: c8736576-14e9-464f-bd16-18d9b192636f
Producing event: c21894d7-5743-46ca-аc26-003ce0496359
Producing DUPLICATE: c8736576-14e9-464f-bd16-18d9b192636f
Producing event: fc8287af-3ea9-4d4a-b942-35ffbf021059
Producing event: bf46d5b0-06d7-4007-96af-a2bfccbbce7b
Producing event: 960cf295-b4a9-4060-97ff-ee8d1d72e7a2
Producing event: fffaec49-009e-4f05-9656-2f7a8097f4d2
Producing event: 32f44ab3-1d2d-4ce5-b56e-518337ee8439
Producing DUPLICATE: fffaec49-009e-4f05-9656-2f7a8097f4d2
Producing event: 98d8af47-83e4-4ef9-a8f2-f08ebc0e210e
Producing event: eb1569b1-d9d8-4ee0-b280-b6f13544e3ec
Producing event: 97ea2807-5227-4c3d-80bc-b70bdda9efb5
Producing event: 96998244-0370-4911-887d-9247013a1cbe
Producing event: 95c3a767-3204-4448-ab19-a536ac8cc45d
Producing DUPLICATE: 96998244-0370-4911-887d-9247013a1cbe
Producing event: a2a84bba-c831-4ed1-8741-bc68b35d7c38
Producing event: 15932a3c-98cb-48fa-894d-d4e44403fb6e
Producing event: 70b7af79-4946-4053-972a-32ffbe519321
Producing event: a56f67ba-5c5e-4ccb-a6c8-71c35e6c6700
Producing event: e9d5faac-1275-4c66-82fb-4445f9d2cf0f
Producing DUPLICATE: a56f67ba-5c5e-4ccb-a6c8-71c35e6c6700
Now that everything is running. It is time for us to verify the result in ClickHouse.
$ docker-compose exec clickhouse clickhouse-client
Now let’s run some queries:
-- Check unique events
gfc :) SELECT count() FROM users_dedup;
SELECT count()
FROM users_dedup
Query id: a3678d6b-6f30-4022-9844-1a10e8146770
┌─count()─┐
│ 300 │
└─────────┘
1 row in set. Elapsed: 0.008 sec.
-- Sample some events
gfc :) SELECT * FROM users_dedup LIMIT 5;
SELECT *
FROM users_dedup
LIMIT 5
Query id: 3ec29919-a494-45f1-bbe5-216e1436aaac
┌─event_id─────────────────────────────┬─user_id──────────────────────────────┬─name───────────┬─email──────────────────────┬──────────created_at─┐
│ 0b225f88-3aef-4678-8001-1257d075a0cd │ 6de2dc80-1149-497f-91c7-0d225993a5a7 │ holmeslance │ tracey06@example.com │ 2025-05-09 00:05:32 │
│ c35495aa-2909-4a9e-8001-1ea777a23997 │ 90ea6f88-b0b2-4f0e-be50-d9884640b6aa │ jacksonjanet │ urios@example.net │ 2025-05-08 23:50:34 │
│ a5932216-f484-4b1f-8003-5225f8fc95cb │ e8cf94c5-2c88-4145-8d7c-7d701bdc9da7 │ iedwards │ rodriguezjill@example.net │ 2025-05-08 23:49:50 │
│ b48e7b7b-d54f-4e66-8006-b90c5028ac29 │ f812f5bc-31c1-44ef-9ccf-0b284d7b4344 │ sharonbuchanan │ johnsondonna@example.com │ 2025-05-09 00:50:00 │
│ e39d1fa6-7889-4b42-8006-be2bdc05e4e4 │ 48e6ef29-e499-4de5-b4cb-420ffab30195 │ burnettronald │ melindamathews@example.net │ 2025-05-09 00:49:53 │
└──────────────────────────────────────┴──────────────────────────────────────┴────────────────┴────────────────────────────┴─────────────────────┘
5 rows in set. Elapsed: 0.037 sec.
-- Make sure that there is only one item registered for the duplicated item
gfc :) SELECT count() FROM users_dedup WHERE event_id='c8736576-14e9-464f-bd16-18d9b192636f';
SELECT count()
FROM users_dedup
WHERE event_id = 'c8736576-14e9-464f-bd16-18d9b192636f'
Query id: 199b5702-36dd-4dae-bca4-8b6cf533d1f4
┌─count()─┐
│ 1 │
└─────────┘
1 row in set. Elapsed: 0.038 sec.
Note on Deduplication in Kafka and ClickHouse
Some of the readers might ask why we need to go through all this trouble. Let’s go through this question in this section.
While Kafka excels at handling high-throughput event streams, it does not provide native deduplication—leaving it up to developers to implement this critical functionality. Kafka guarantees message delivery but does not filter duplicates, leading to several pain points like: Producer-side duplicates where a producers might retry sending the same message multiple times (e.g. due to network blip). Consumer-side replays where during consumer group rebalances or failures, Kafka may reprocess already-consumed messages. No cross-topic deduplication where if the same event is written to multiple topics (e.g. purchases and customer_activity), Kafka treats them as entirely separate streams. Even when you use enable.idempotence in Kafka it only helps with producer-side duplicates.
At the same time, ClickHouse, while optimized for analytical queries, presents its own challenges when used for real-time deduplication. Checking for duplicates via ClickHouse queries adds milliseconds of latency per event—problematic for high throughput streams. ClickHouse lacks an atomic INSERT IF NOT EXISTS operation, requiring workarounds like using tables with TTL. But this also create new problems. Expired records may linger briefly, causing false negatives if a new duplicate arrives before cleanup. Heavy write/read loads on the tables can slow down analytical queries on the main dataset.
Another alternative is to use ReplacingMergeTree when creating a table in ClickHouse. However, due to its implementation, ReplacingMergeTree might not fit your use case. To learn more about this please visit our previous article.
Conclusion
In modern data architectures, duplicate events are inevitable—whether from producer retries in Kafka, multi-system integrations (like CRM and ad platforms), or consumer reprocessing. These duplicates distort analytics, waste resources, and degrade user experiences, yet Kafka provides no built-in deduplication, while ClickHouse’s strengths as an analytical database introduce latency and scalability trade-offs when used for real-time duplicate tracking. This article walked through building a practical deduplication pipeline using Kafka for ingestion, ClickHouse, and GlassFlow for processing, implementing a time-bound sliding window to filter duplicates. The solution serves as a foundational pattern. Ultimately, streaming deduplication isn’t just a technical fix—it’s a prerequisite for trustworthy data in an increasingly multi-source world.
Where to go from here
To learn more about this topic, you can take a look at the following resources:


Top comments (0)