Postgres' popularity is steadily increasing. It is the most popular open-source relational database available, and with almost 40 years of development, it is an excellent choice for applications of all sizes. However, starting with Postgres can feel like climbing a mountain, and just like learning anything new, you will undoubtedly make mistakes. Although mistakes are a regular part of the learning experience, they can be time-consuming and difficult to debug. So why not avoid them in the first place?
Common Beginner Mistakes
Here are the six common PostgreSQL mistakes beginners should avoid to maintain efficient and secure database environments.
1. Not Understanding What VACUUM Is or When to Use It
Understanding and using VACUUM accurately is important for maintaining a healthy and performant PostgreSQL database. VACUUM is a powerful command that reclaims storage occupied by dead tuples (dead rows). When a vacuum process runs, it marks the space occupied by dead tuples as reusable by other tuples.
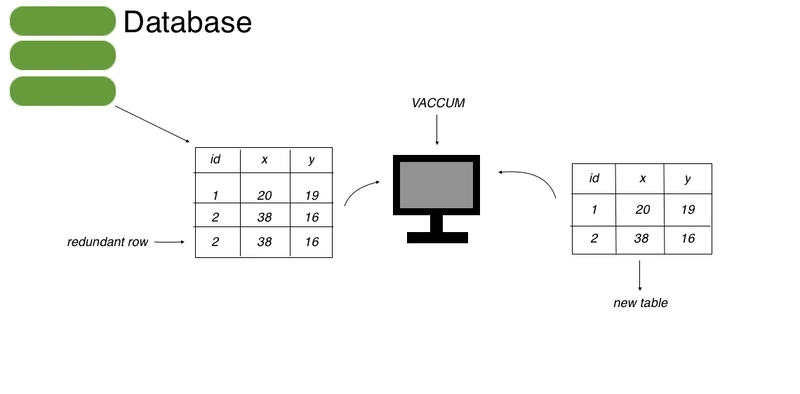
2. Forgetting to Close Connections
Every time you open a connection, either to fetch or update data, it takes time and utilizes resources like memory and CPU. If these connections are not closed properly after use, they remain open and idle, consuming system resources and eventually running out of the database’s connection limit. This is called a connection leak and can result in errors and downtimes.
3. Writing Inefficient Queries
If you’re working with many rows from a big table, you must be careful while writing queries because it can be tricky. An unoptimized query may scan the table or touch significantly more rows than necessary.
4. Forgetting to Add Primary Keys, Impacting Data Integrity
Whenever you create tables in your Postgres database, define primary keys. Without a primary key, the table lacks a unique identifier for each row, making it impossible to enforce data integrity and leading to problems such as duplicate rows. Over time, this can lead to inconsistent data, ruptured relationships, and unreliable query results.
5. Overcomplicating Schema Design
A database schema is any structure that you define around the data. This includes views, tables, relationships, fields, indexes, functions, and other elements. Without any of these, getting lost in a database is easy.
6. Overlooking the Importance of Backups
Data loss is a nightmare scenario, whether caused by a malicious attack, human error, or a software bug. One of the common mistakes that most developers new to Postgres or working with databases make is overlooking the importance of backups, and the consequences could be devastating.
Tackling Schema Changes, Autoscaling, and Backups the Smart Way
Managing large databases often leads to issues like downtime during schema upgrades, backup complexities, and scaling challenges. Neon addresses these with a serverless PostgreSQL solution focused on flexibility and resilience. It supports popular schema migration tools like Alembic and Flyway to minimize disruption.
Neon also enables autoscaling to handle workload spikes automatically. It offers automatic backups and point-in-time recovery (PITR) for data recovery, ensuring easy restoration after failures. Backup options include PITR for precise recovery, pg_dump for manual snapshots, and GitHub Actions for automated, external backups—each catering to different recovery needs.
Check out the full article by Neon here.



Top comments (0)