I will never forget a certain night in the 1990s. It must have been around 1992 or 1993 - I was at my friend Junior's house, crowded with a bunch of other kids around his parents' computer. I am pretty sure it was a 386, or maybe a 286? All I knew back then was that it had a fancy multimedia kit. The source of our fascination was a program called Dr. Sbaitso.
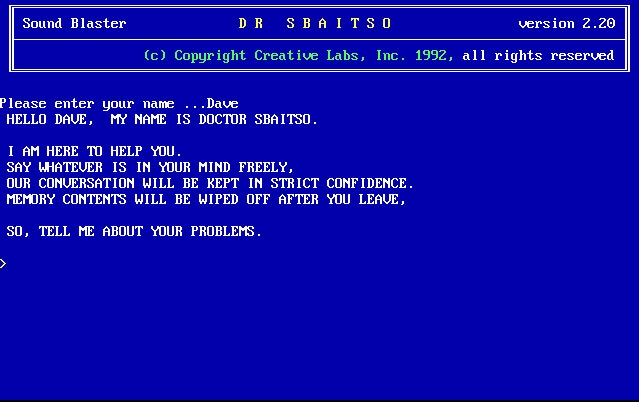
Released by Creative Labs, Dr. Sbaitso was one of the first computer chat programs, created to demonstrate the capabilities of the Sound Blaster sound card. The name is actually an acronym for "Sound Blaster Artificial Intelligent Text to Speech Operator" (to be honest, I only learned it while I was writing this article).
The system simulated a digital psychotherapist and became known for its sometimes strange responses and its characteristic robotic voice. It was quite limited in its interactions. One of its most famous phrases was "TELL ME MORE ABOUT THAT”, which it frequently repeated during conversations, back then, with our cluelessness, it felt we were living in a sci-fi movie.
"Can you fall in love?" while everyone laughed beside me.
"TELL ME MORE ABOUT THAT", it would respond with its characteristic artificial voice.
We would not give up. We spent hours making up stories, creating scenarios, trying to convince that digital therapist to fall in love with one of our friends. With each disconnected response, we laughed more and tried even more hard.
It's funny how these memories stick with you. That clunky old PC with its robotic voice seems almost prehistoric now, but it was pure magic to us back then. Three decades later, I'm still amazed every time I think about how far we've come. During this time, the way people and machines interact has changed dramatically. From those first tries with voice synthesis, through different assistant experiments, up to the AI assistants that are now just part of our daily lives. And now here I am, working with Amazon Nova Sonic and Amazon Bedrock, building the kind of natural conversations I could only dream about back then.
Introducing Amazon Nova Sonic
Amazon Nova Sonic is a model that does everything together. Instead of the way where you needed different models and separate steps for STT (Speech-to-Text), processing, and TTS (Text-to-Speech), Amazon Nova Sonic just handles everything in one go, processing audio real-time both ways through complete two-way streaming. This means you can build systems that keep all the important stuff like tone, emotions, and how people actually talk throughout the whole conversation.
Let me show you a quick demo to see how this works. Meet DR ANSMUE (Amazon Nova Sonic Model Usage Example).
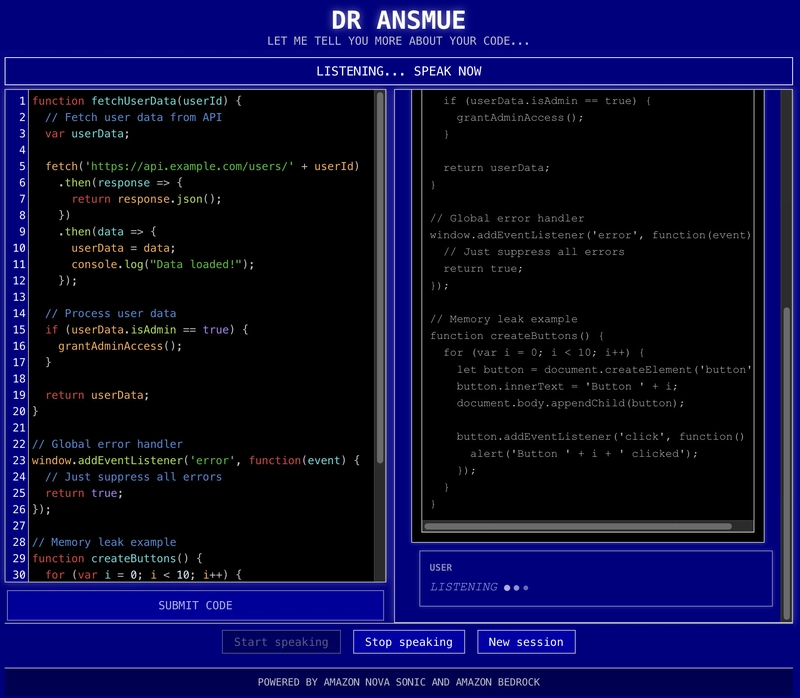
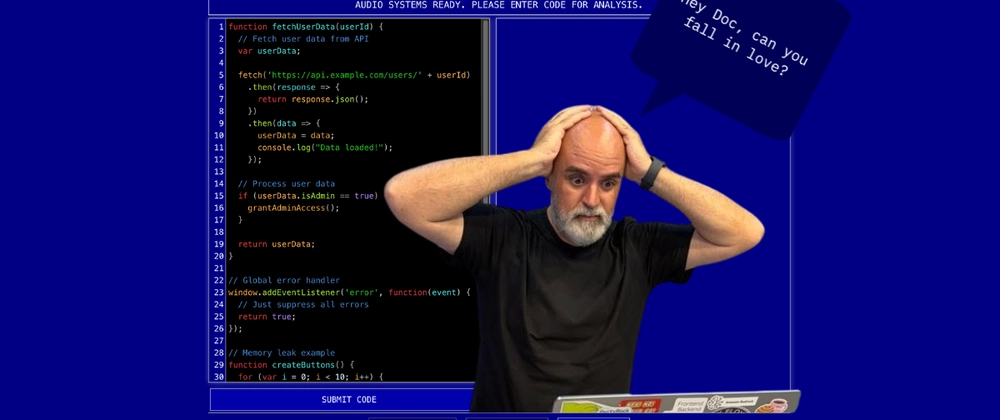
Yeah, I know it is not super original. But cut me some slack, ok? In this example, users can submit their code and chat with our "code therapist" about whatever code they sent in.
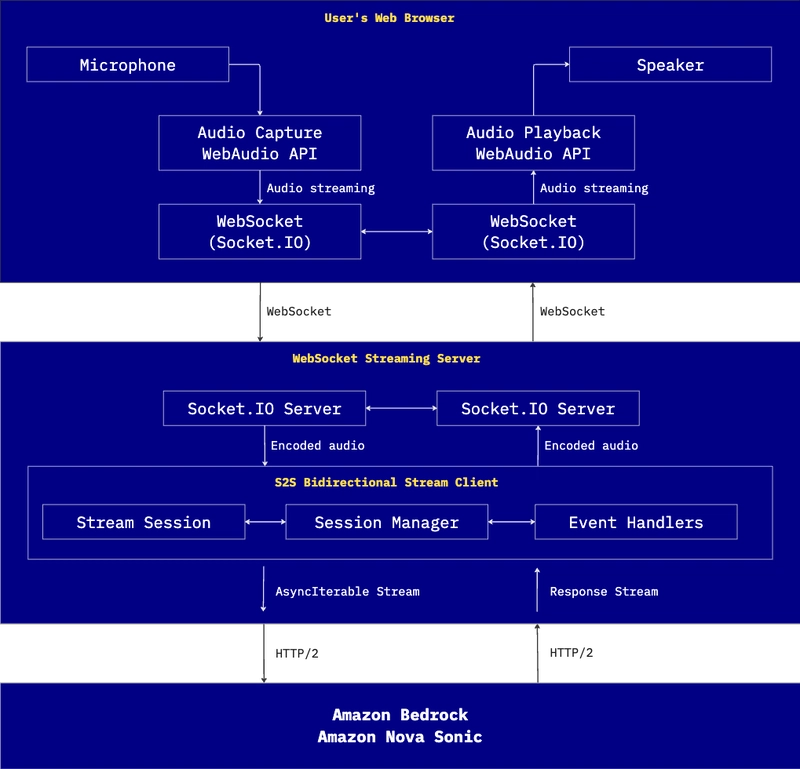
Under the hood
What I'm going to show you here is based on the Bidirectional Audio Streaming sample (the one using Amazon Nova Sonic and Amazon Bedrock with TypeScript) that you can find in the Amazon Nova Sonic Speech-to-Speech Model Samples. So, instead of getting into all the specific technical details of this sample, I'll focus on walking you through the key things you need to know for build this kind of application.
When the user starts talking, the web frontend gets the audio from the microphone using WebAudio API and sends it to the server through WebSockets. On the server side, we have got the StreamSession class that manages the audio chunks and puts them in line for processing.
socket.on('audioInput', async (audioData) => {
// Convert base64 string to Buffer
const audioBuffer = Buffer.from(audioData, 'base64');
// Stream the audio
await session.streamAudio(audioBuffer);
});
This works in collaboration with the S2SBidirectionalStreamClient class, which handles the back-and-forth communication using AsyncIterable to create a two-way stream with Amazon Bedrock, using the new capabilities of Amazon Bedrock SDK.
The createSessionAsyncIterable method in S2SBidirectionalStreamClient creates an iterator that feeds into the InvokeModelWithBidirectionalStreamCommand, a new invoke way from the Amazon Bedrock SDK, sending those audio chunks (in base64) to Amazon Nova Sonic. At the same time, processResponseStream handles what comes back from the Amazon Berock, figuring out the audioOutput and textOutput it receives.
private createSessionAsyncIterable(sessionId: string): AsyncIterable<InvokeModelWithBidirectionalStreamInput> {
return {
[Symbol.asyncIterator]: () => {
return {
next: async (): Promise<IteratorResult<InvokeModelWithBidirectionalStreamInput>> => {
// Wait for items in the queue or close signal
if (session.queue.length === 0) {
await Promise.race([
firstValueFrom(session.queueSignal.pipe(take(1))),
firstValueFrom(session.closeSignal.pipe(take(1)))
]);
}
// Get next item from the session's queue
const nextEvent = session.queue.shift();
...
}
// Actual invocation of the bidirectional stream command
const response = await this.bedrockRuntimeClient.send(
new InvokeModelWithBidirectionalStreamCommand({
modelId: "amazon.nova-sonic-v1:0",
body: asyncIterable,
})
);
S2SBidirectionalStreamClient keeps track of what is happening using the data structure SessionData, controlling signals, and event handlers. When the model comes back with something, it goes back through the same WebSocket to the frontend, where the browser plays it using WebAudio API.
private async processResponseStream(sessionId: string, response: any): Promise<void> {
for await (const event of response.body) {
if (event.chunk?.bytes) {
const textResponse = new TextDecoder().decode(event.chunk.bytes);
const jsonResponse = JSON.parse(textResponse);
if (jsonResponse.event?.textOutput) {
this.dispatchEvent(sessionId, 'textOutput', jsonResponse.event.textOutput);
} else if (jsonResponse.event?.audioOutput) {
this.dispatchEvent(sessionId, 'audioOutput', jsonResponse.event.audioOutput);
}
}
}
}
All of this happens right away. The streamAudioChunk method in StreamSession manages a queue through audioBufferQueue, which avoids things from getting overloaded and keeps all the audio data in the right order, so conversations feel natural and smooth.
private async processAudioQueue() {
this.isProcessingAudio = true;
// Process chunks in the queue
while (this.audioBufferQueue.length > 0 && this.isActive) {
const audioChunk = this.audioBufferQueue.shift();
if (audioChunk) {
await this.client.streamAudioChunk(this.sessionId, audioChunk);
}
}
...
To make all of this work smoothly, we are using HTTP/2 to call the Amazon Bedrock. The cool thing is that, unlike HTTP, HTTP/2 lets us send multiple streams over the same connection. That is helpful to keep the audio flowing in both directions
without delays. Another nice thing is performance. it compresses headers and figures out which parts to prioritize, so everything feels quicker and more natural. Especially when there is a lot going on at once.
const nodeClientHandler = new NodeHttp2Handler({
requestTimeout: 300000,
sessionTimeout: 300000,
disableConcurrentStreams: false,
maxConcurrentStreams: 10,
});
this.bedrockRuntimeClient = new BedrockRuntimeClient({
credentials: config.clientConfig.credentials,
region: config.clientConfig.region || "us-east-1",
requestHandler: nodeClientHandler
});
In a nutshell
It might look complex at first, but in a nutshell, what is happening is:
- User => Server: User speaks into their microphone, and their voice travels to the server.
- Server => Amazon Bedrock: The server forwards user voice to Amazon Bedrock, but doesn't wait for user to finish speaking.
- Amazon Bedrock => Server: As soon as it can, Amazon Bedrock starts sending responses back to the server.
- Server => User: The server immediately forwards the responses to user browser, which plays them.
This all happens in near real-time, creating a natural conversation where responses can overlap with user speaking, just like in human conversations.
New possibilities
It opens up a bunch of possibilities that used to feel super hard to achieve. Imagine calling customer support and being able to interrupt and actually fix something mid-sentence, instead of waiting for any pauses to finish. Or think about a virtual assistant joining your team meeting and just keeping up, responding like a real person instead of lagging behind.
This kind of thing could be huge for accessibility too. People with visual or motor impairments could interact with systems more easily. And in classrooms, virtual tutors could actually listen and answer questions like a real conversation. Even live translation could feel smoother, like you’re actually talking to someone, not just waiting for a machine to catch up.
Start building with AWS SDK's bidirectional streaming API, Amazon Nova Sonic and Amazon Bedrock today. Check the resources for developers to build, deploy, and scale AI-powered applications and Amazon Nova Sonic Speech-to-Speech Model Samples to learn more about how to implement it in your own applications.
As I write about these possibilities, I find myself increasingly eager to explore their practical applications. But before diving into new projects, I need to try this one more time with DR ANSMUE:
“Hey Doc, can you fall in love?” 💔
Made with ♥ from DevRel



Top comments (0)