
Timestream for LiveAnalytics is a serverless, purpose-built database for processing time-series data. While it efficiently ingests and stores data, querying large raw datasets frequently can be inefficient, especially for use cases like aggregations, trend analysis, or anomaly detection.
Scheduled Queries is a feature of timestream help addressing this by running SQL queries at specified intervals, rolling-up raw data into aggregated results, and storing them in a destination Timestream table. This approach improves performance on target tables, and optimises storage by retaining only the aggregated data.
In this post, we’ll walk through setting up Timestream Scheduled Queries to automate data rollups. We’ll also explore how this setup helps you analyze and detect trends in your data over time.
What are we going to build ?
As a use case, we’ll have a clickstream kinesis topic where producers can push events such as clicks, views, and user actions. These events will be ingested into a Timestream table and made available for downstream consumption. A scheduled query will run hourly to roll up raw event data, which will then be used to detect trending products.

Let’s dive into this:
Time Series store: With EventBridge Pipes supporting Timestream as a direct target, integrating with Kinesis stream source is simple. This eliminates much of the custom glue code needed for ingestion. In this setup, EventBridge Pipes polls the Kinesis stream, converts the received events into records, and writes them directly to the Timestream table.
A scheduled aggregation query runs at predefined intervals to process raw events, performing an hourly rollup and storing the results in a dedicated table. Once it successfully completes, it publishes a notification event that triggers a function to query the table and detect the top N trending products, which are then published to a topic. We can imagine that these events can be used for various purposes: adjusting ad spend or fine-tuning A/B tests. Additionally, the rolled-up data can be fed into dashboards like QuickSight, Tableau, or Grafana for visualizing and monitoring product performance.
☝️Note: While I won't go into detail in this post, it's worth noting that a common way to reduce writes to the raw table is by pre-aggregating data in small batches, such as using a 5-minute tumbling window. This groups events into fixed, non-overlapping intervals before writing, effectively lowering the write frequency. Managed Apache Flink can help achieve this.
Let’s see the code
In this section, I will mainly focus on the integration with EventBridge Pipes as well as the scheduled query configuration. You can find the complete end-to-end solution at the following link 👇
https://github.com/ziedbentahar/scheduled-queries-with-amazom-timestreamdb
Simplifying time-series data ingestion with event bridge pipes
The events ingested into Kinesis are quite basic; they contain only the productId, pageId, eventType, and the event timestamp. Configuring a Timestream table as a target in EventBridge Pipes requires defining the mapping from the source event to the selected measurements and dimensions in the target table. This also involves specifying the time field type and format:
resource "awscc_pipes_pipe" "kinesis_to_timestream" {
name = "${var.application}-${var.environment}-kinesis-to-timestream"
role_arn = awscc_iam_role.pipe.arn
source = var.source_stream.arn
target = aws_timestreamwrite_table.events_table.arn
source_parameters = {
kinesis_stream_parameters = {
starting_position = "TRIM_HORIZON"
maximum_retry_attempts = 5
}
filter_criteria = {
filters = [{
pattern = <<EOF
{
"data": {
"eventType": ["pageViewed", "productPageShared", "productInquiryRequested"]
}
}
EOF
}]
}
}
target_parameters = {
timestream_parameters = {
timestamp_format = "yyyy-MM-dd'T'HH:mm:ss.SSS'Z'"
version_value = "1"
time_value = "$.data.time"
time_field_type = "TIMESTAMP_FORMAT"
single_measure_mappings = [{
measure_name = "$.data.eventType"
measure_value = "$.data.value"
measure_value_type = "BIGINT"
}]
dimension_mappings = [
{
dimension_name = "id"
dimension_value = "$.data.id"
dimension_value_type = "VARCHAR"
},
{
dimension_name = "pageId"
dimension_value = "$.data.pageId"
dimension_value_type = "VARCHAR"
},
{
dimension_name = "productId"
dimension_value = "$.data.productId"
dimension_value_type = "VARCHAR"
}
]
}
}
}
Here, I am filtering and ingesting only the pageViewed, productPageShared, and productInquiryRequested events into the table from the stream.
We can view the details of the deployed pipe in the console:
 Kinesis to timestream, filtering events
Kinesis to timestream, filtering events
You can view and edit the configured mapping for the target data model in the console… but when it comes to editing, you should always use IaC! Unless, of course, you enjoy the thrill of undocumented changes 😉
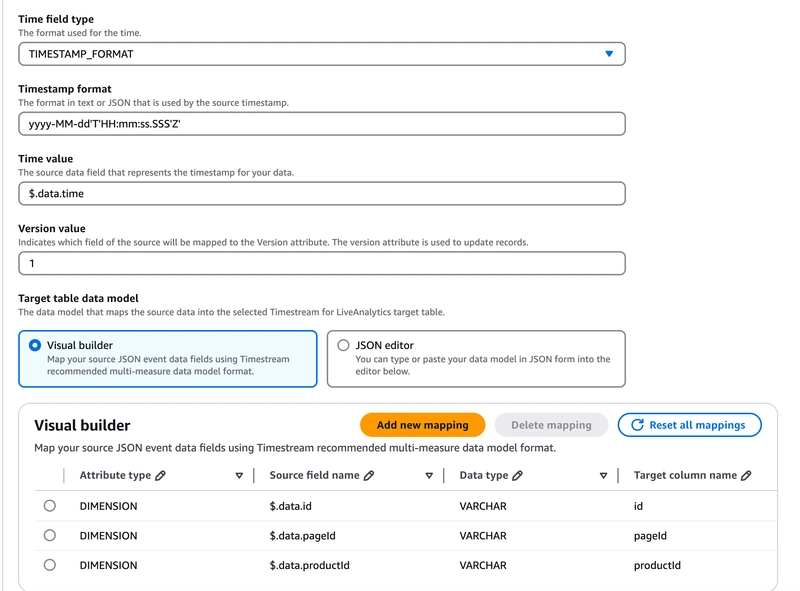 Configuring table data model from the console
Configuring table data model from the console
Automating the creation of the scheduled queries
Creating the scheduled query requires defining the schedule configuration, the query statement, and the target mapping, ensuring that the results are properly mapped to the data model for insertion into the destination table.You also need to define an SNS topic to publish notifications about the execution status of scheduled queries.
resource "aws_timestreamquery_scheduled_query" "hourly_rollup" {
name = "${var.application}-${var.environment}-hourly-rollup"
schedule_configuration {
schedule_expression = "rate(1 hour)"
}
query_string = templatefile("${path.module}/queries/hourly-rollup.sql.tmpl", {
table = "\"${aws_timestreamwrite_table.events_table.database_name}\".\"${aws_timestreamwrite_table.events_table.table_name}\""
})
target_configuration {
timestream_configuration {
database_name = aws_timestreamwrite_database.events_db.database_name
table_name = aws_timestreamwrite_table.hourly_rollup.table_name
time_column = "time"
dimension_mapping {
name = "pageId"
dimension_value_type = "VARCHAR"
}
dimension_mapping {
name = "productId"
dimension_value_type = "VARCHAR"
}
measure_name_column = "eventType"
multi_measure_mappings {
target_multi_measure_name = "eventType"
multi_measure_attribute_mapping {
source_column = "sum_measure"
measure_value_type = "BIGINT"
}
}
}
}
execution_role_arn = aws_iam_role.scheduled_query_role.arn
error_report_configuration {
s3_configuration {
bucket_name = aws_s3_bucket.error_bucket.id
object_key_prefix = local.hourly_rollup_error_prefix
}
}
notification_configuration {
sns_configuration {
topic_arn = aws_sns_topic.scheduled_query_notification_topic.arn
}
}
depends_on = [
aws_lambda_invocation.seed_raw_events_table
]
}
Here is the query:
SELECT
SUM(measure_value::bigint) as sum_measure,
measure_name as eventType,
bin(time, 1h) as time,
productId,
pageId
FROM
${table}
WHERE
time BETWEEN @scheduled_runtime - (interval '2' hour) AND @scheduled_runtime
GROUP BY
measure_name,
bin(time, 1h),
productId,
pageId
To account for late-arriving events, it processes data in a two-hour window, ensuring delays of up to two hours are included in the roll-up.
☝️ Note: As of the time of writing, in order to create a scheduled query, the source table must contain data; otherwise, the creation will fail. To enable fully automated IaC deployment, I will add a Lambda invocation resource that triggers immediately after the source events table is created. This Lambda function will insert dummy events into the table, ensuring that the scheduled query can correctly infer the target schema during its creation:
resource "aws_lambda_invocation" "seed_raw_events_table" {
function_name = aws_lambda_function.seed_raw_table.function_name
input = jsonencode({})
depends_on = [
aws_lambda_function.seed_raw_table,
aws_timestreamwrite_table.events_table
]
lifecycle_scope = "CREATE_ONLY"
}
Once deployed, you can head straight to the Timestream schedule queries page . Here’s what it looks like:
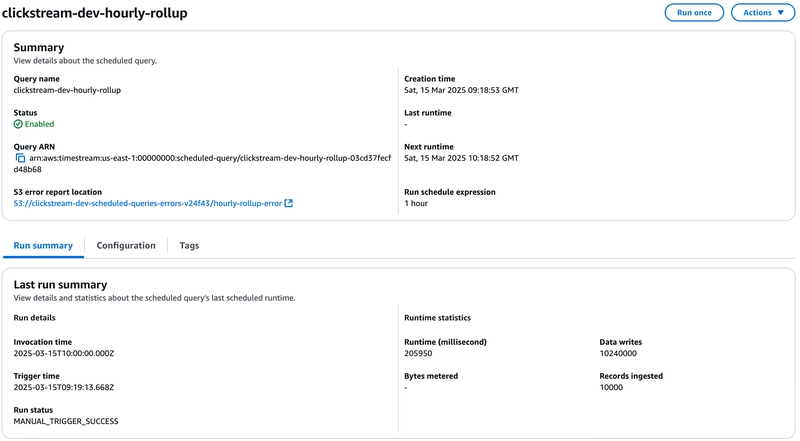
Identifying trending products
The “handle hourly roll up” function subscribes to the scheduled query execution events and runs a trend analysis that compares the page views per product of the last hour to the previous hour to identify the top N products that have achieved 2x views. It then publishes an event for these products.
Below is how this function queries the Timestream table using the Timestream Query Client:
const getTopNProduct = async (params: { eventType: string; topN: number }): Promise<TrendingProducts> => {
const { eventType, topN } = params;
const qs = `
WITH LastHour AS (
SELECT
productId,
sum_measure AS current_views
FROM "${db}"."${table}"
WHERE measure_name = '${eventType}'
AND time > ago(1h)
),
PreviousHour AS (
SELECT
productId,
sum_measure AS previous_views
FROM "${db}"."${table}"
WHERE measure_name = '${eventType}'
AND time > ago(2h)
AND time <= ago(1h)
)
SELECT
l.productId,
l.current_views,
COALESCE(p.previous_views, 0) AS previous_views,
(l.current_views - COALESCE(p.previous_views, 0)) AS increase_last_hour
FROM LastHour l
LEFT JOIN PreviousHour p ON l.productId = p.productId
WHERE (l.current_views >= COALESCE(p.previous_views, 0) * 2)
ORDER BY increase_last_hour DESC
LIMIT ${topN}
`;
const queryResult = await timestreamQueryClient.send(
new QueryCommand({
QueryString: qs,
})
);
const result = parseQueryResult(queryResult);
return {
eventType,
time: new Date().toISOString(),
products: result.map((row) => ({
productId: row.productId,
count: Number(row.current_views),
increaseLastHour: Number(row.increase_last_hour),
})),
};
};
The Timestream SDK returns query responses in a raw format. To make them more usable, I drew heavy inspiration from this code example provided in an AWS Labs repository to parse the query result.
For comparison, here’s the same query executed on both the raw events table and the hourly roll-up table for a synthetic dataset of 200,000 ingested events:

Even with this relatively small dataset and its distribution, we can observe a clear difference in both the query duration and the number of bytes scanned between the two tables.
Wrapping up
I hope you find this article useful! We explored how to leverage Timestream for live analytics, focusing on automating data rollups to optimise query performance.
As always, you can find the full code source, ready to be adapted and deployed here:
https://github.com/ziedbentahar/scheduled-queries-with-amazom-timestreamdb
Thanks for reading !

Top comments (0)